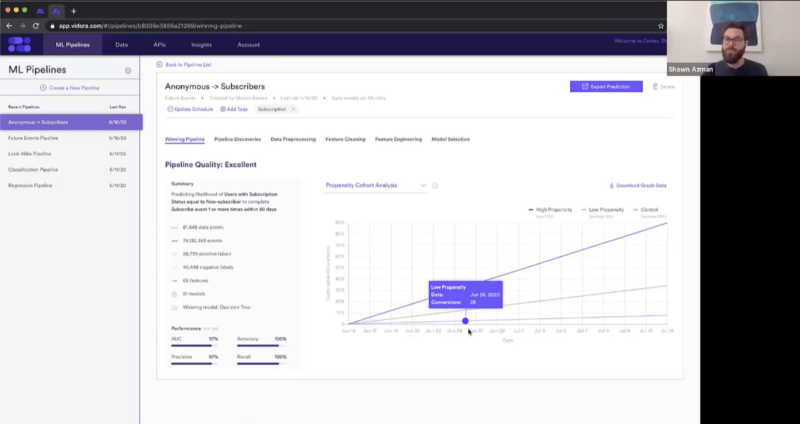
Watch our ongoing series on how automated machine learning can accelerate personalization strategies and ROI for enterprise marketers and product managers.
Converting Anonymous Users to Registered Users [Part 1]
For enterprise business teams, data silos can inhibit an effective data strategy. And a lack of qualified data science, engineering, and critical domain hampers the effectiveness of many teams who are flying blind with their anonymous users.
In the new world of AI 2.0, these challenges can be overcome with a maniacal focus on these discrete pain points – data siloes, lack of automation, talent, and a perceived investment risk without clear ROI.
Add on top of this the vanishing of 3rd party cookie data, and business teams that adopt and enable machine learning within their teams and organizations will survive and thrive in the new era of commerce and content.
Machine learning is no longer an R&D project that sometimes sees the light of day, it’s a platform that enables business teams to continuously learn from recent data, plan, test, iterate, and gain ROI in a matter of weeks.
The challenges remain the same: Personalizing the digital experience for people who will engage, re-engage, and eventually become loyal and paying customers.
Watch Part 1 of our segment below and see how easy it is to setup a prediction that your team can launch and act on in near real-time to predict the behaviors that will drive anonymous users to convert or subscribe.

Contact
Contact us using the form below to learn more about Vidora. We’re excited to hear from you!
—Read the full interview below—
Aaron Huang:
Hey everyone, I’m Aaron, head of product marketing, and I’m here again with Shawn, our head of solutions engineering at Vidora. Thanks for taking the time to tune in with us in our ongoing series of Vidora’s Cortex, highlighting kilo-use cases for automating data science and machine learning. The use case we’re walking through today, predicting the likelihood of anonymous users converting to registered users. It’s a perennial challenge for all business teams that have digital storefronts, whether it’s eCommerce, real estate, online media. One of the biggest indicators really of real intent or engagement is this critical registration. So Shawn, as always, thanks for spinning this up and walking us through Cortex today.
Shawn Azman:
Yeah definitely, happy to be here.
Aaron Huang:
Shawn, so anonymous and registered users. Right off the bat, how are business teams trying to predict this behavior today, and how can Cortex help them do that?
Shawn Azman:
Yeah, definitely. This is quite a difficult thing to predict, because if you just think about the amounts of data that you’re capturing for your current customers, your current members, and compare that to the amount of data that you have for these anonymous or non-subscribed users, it’s usually just a lot less data that you know about these customers. You obviously don’t have an email address, you don’t have a phone number, you have no way to reach out to them. And so essentially what you’re trying to do is find patterns of usage behavior that you can map to what’s most likely to become a registered user. And if you’re just using typical analytic reports, which a lot of customers do before they transition to a machine learning approach, you’re using sort of very high-level metrics. Again, because these aren’t typically known users, it’s typically page views, maybe you can track if they come back over time, but you’re usually limited in the scope. And so usually, you’re trying to take these sort of high-level analytic metrics, and guess if those are going to be good indicators of users who are going to become subscribers.
Aaron Huang:
Right. Yeah, so let’s talk about data pipelines here, because obviously this is something that we’ve actually done in the past, to use Google Analytics or Mixpanel or what have you. We have Omniture. And I’m basically making essentially educated inferences, to your points. How does the actual data pipeline work for Cortex, in terms of enhancing the ability for a business team to actually make this prediction?
Shawn Azman:
Yeah, definitely. Really where the power of machine learning in Cortex comes in is doing that finding of those behavior patterns for you, and this is where a lot of the automation of Cortex comes in. Because we’re using this big data approach, we can look through usage patterns across all of your different users and say, okay, what were those usage patterns before they registered, and what were those usage patterns after they registered? And we can start to suss out these details that maybe you wouldn’t be able to find on your own if all that you were doing was looking at aggregate analytic reports. And so it’s really that idea to be able to break it down on per user, per individual basis, find usage patterns, and then map that to the registration. That’s really where the power of machine learning in Cortex is going to come. And as you mentioned, all the data needed to do that comes exactly from those analytics providers. And so as long as we’re getting those usage patterns attached to those users, we can usually make this inference of, okay, these are the types of pattern behaviors it looks for anonymous users to eventually become registered users.
—-Competitive Advantages: Speed-to-Prediction and Continuous Learning—
Aaron Huang:
Got you, okay. And I know you’re going to walk into a specific example of that a little bit in terms of data types and actually populating the data pipeline. One of the things I think we’ve been talking about continually in the past three months is this dramatic shift in user behavior over a very short time. So in the past, potentially that actually might work in converting an anonymous registered user may not work in the last three months or going forward. How does Cortex allow these teams to remain nimble and adapt to these changes? Some of this goes around potentially the automation machine learning, some of this goes around the automation data science, but in particular in the last few months, we’ve seen a dramatic almost phase shift of user behavior. How can we actually leverage the Cortex to basically help these business teams adapt very quickly?
Shawn Azman:
Definitely, and I think you mentioned the key word, which is continuous. And when we think of a continuously learning machine learning model, there’s really two parts to that. One is the ability to capture and feed new data into your machine learning pipeline, and the second is that pipeline taking it and actually retraining its model based on that new data so that our predictions are most up to date. And so when it comes to Cortex, we do both. And so the whole idea is, it’s not just a one-time model that’s trained based on data that you had in the past, and then you’re stuck using that model to predict more usage patterns in the future. Really, what we do with our customers is integrate to ensure that we’re continuously getting new data. Some customers stream data to us just like they do their analytics providers. Others do it, say, on a daily basis, where they dump data over to Cortex. But the key idea there being that all of these new usage patterns are continuously being streamed over into Cortex. So that’s one aspect, is ensuring that you’re just capturing the new data.
Shawn Azman:
And then the second aspect is to use that data to retrain and update your predictions for each user, and this is really where the Cortex automation truly comes into play. Because oftentimes, when you look at machine learning models built in-house, they’re often not built with this idea of continuous learning as a core feature. More often than not, they’re built with sort of a historic dataset to train a model. And then like I said before, that model is then used throughout the future, and the further away you get from the training of that model, the less accurate that prediction is going to be. Especially as you mentioned, if we’re seeing drastic changes in user behavior.
Shawn Azman:
And so Cortex automation does both of these for you. We’ll continuously ingest new data from you, and use that new data to continuously retrain and update the predictions for each one of your users. That way, if week over week we’re starting to see patterns change, our models will update automatically based on that change of behavior. And anytime you use that prediction, you can rest assured that it’ll have the most up to date prediction for that user based on any of these behavior patterns.
—-Automating Machine Learning: Data Types and Integrations—
Aaron Huang:
Got you, okay. Well, I guess let’s get really specific here, as we kind of tee up the interface here. What types of data are we talking about? I know obviously we’re talking about a registration action, or some sort of an event data. But what other types of data actually go into the interface or into the system, and how do we actually run those pipelines?
Shawn Azman:
Yeah, definitely. So especially for these types of predictions, more often than not what we’re getting is sort of website or other behavior data. And really, we can take any and all of that, and that’s what’s going to power the machine learning within Cortex. And so when we think of the types of data that we’re going to capture, it’s all of the events and timestamps for each user, and then if we happen to know any attributes about that user, we can capture that too. You can think of attributes being more static, like the location that they’re coming from, maybe what device or platform on which they’re operating, versus the events that can happen multiple times, like you can click a button multiple times.
Shawn Azman:
And those are the two main datasets that we’re going to use to create this prediction. And so specifically for these types of use cases, this data simply comes from the analytic provider that you’re using. I think you mentioned a few, Google Analytics, Omniture, Salesforce if you’re using them for a marketing cloud. A lot of these analytic providers are going to capture data in exactly that right format to be ingested into Cortex. Events for users at a given time, updated with attributes, either about the event that’s occurring or about that user. And the great thing about Cortex is that we can ingest this data from multiple different sources. So for example, maybe your website data is separated from your mobile app data, which is separate from your subscription service. We can ingest each of those three different sources of data, and the first step that we do is combine them all so that if one user has actions across all three, we’ll be able to know that and map that into that user’s behaviors before we even create the predictions.
Aaron Huang:
Got you, so you’re basically binding together if you will a notion of a user or a user ID of some sort.
Shawn Azman:
Yeah, that’s absolutely right, and this is actually really important for this particular use case, because typically that’s going to be some kind of user registration membership ID, something that’s known to the customer. But in this use case, that usually doesn’t exist. Typically what we’re working off of here is cookies. And that’s really going to get into what kind of data that you can use for this pipeline, because in the past, we used to be able to augment a lot of this data with third-party data, but third-party cookies are going to be going away, and so really we’re going to be reliant on first-party data here. And that’s why it’s so important to be able to capture the behaviors of any of these users, because it’s really going to be the individual user’s behavior that allow us to make these predictions in the future.


