
User segmentation is a critical component of adtech, marketing, and product strategies. Organizations are increasingly focused on different techniques for segmenting users using declared 1st party attributes in addition to behavioral data. This increasing 1st party data trend is in part driven by the broader secular dynamics surrounding restrictions in using 3rd party data.
Machine learning offers a natural paradigm for building high quality segments given that algorithms are able to learn who belongs in a segment across billions of behavioral signals and declared user attributes. When implemented correctly, machine learning can assure businesses that all their data is being optimally leveraged to create the highest quality segments.
Over the last several years we’ve built in a variety of different tools and techniques to facilitate businesses creating high quality user segments based off of large-scale 1st party data. Below we survey some more common and advanced techniques businesses are using to segment users.
We’ll cover the following machine learning segmentation paradigms, all of which are available in Vidora Cortex –
- Look-Alike
- Classification
- Click-based Optimization
- Uplift Modeling
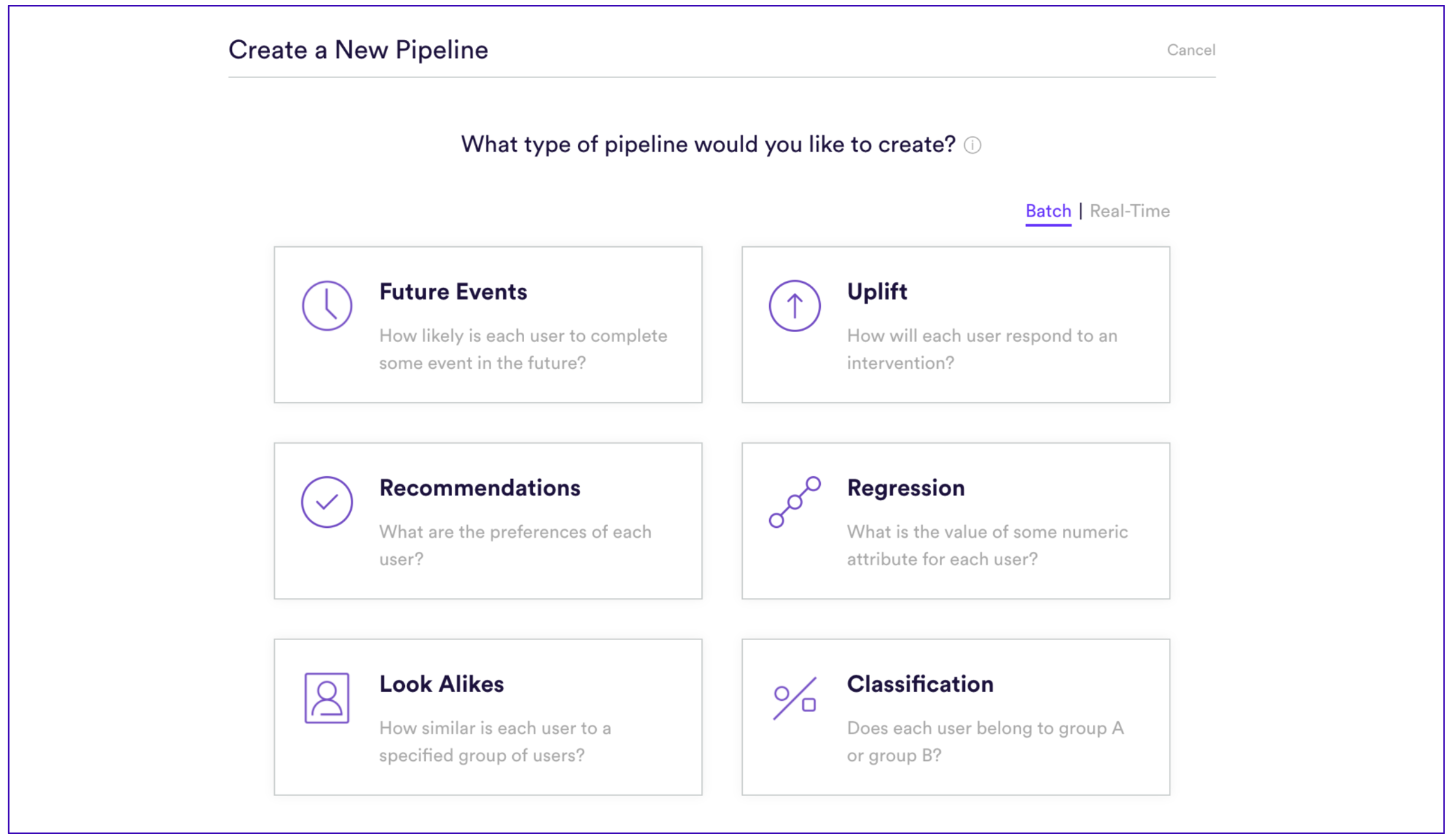
Snapshot of the different kinds of models that can be created in Cortex.
Look-Alike modeling is one of the colloquial terms used to describe segmentation, especially in the adtech space. The basic premise behind Look-Alike modeling is to find similar users to a set of “seed” users. In machine learning parlance this is a type of semi-supervised learning (a fully supervised model would contain both positive and negative examples, as described below for classification models). Look-Alike’s are often offered as part of adtech products and in popular marketing platforms such as Facebook and LinkedIn.
We’ve found that Look-Alike models should be used with caution – when used correctly results can be favorable, but Look-Alikes have several pitfalls which should be considered. A couple learnings we’ve seen working with Look-Alike models –
- Look-Alike models will often latch on to incorrect signals when building a model. Given that there are no explicit “negative” examples (as there are in classification models) the tendency to use the wrong signals to build the model is higher for many real-world use cases. If the algorithm uses the wrong behaviors and attributes to judge the similarity of users, the results will be user segments which don’t reflect the original intent of the modeler.
- If Look-Alike modeling is used it’s important for the modeler to understand and validate the signals used to determine the Look-Alikes. Without the information on which features are used, there is a good chance of building a poor model for the task at hand.
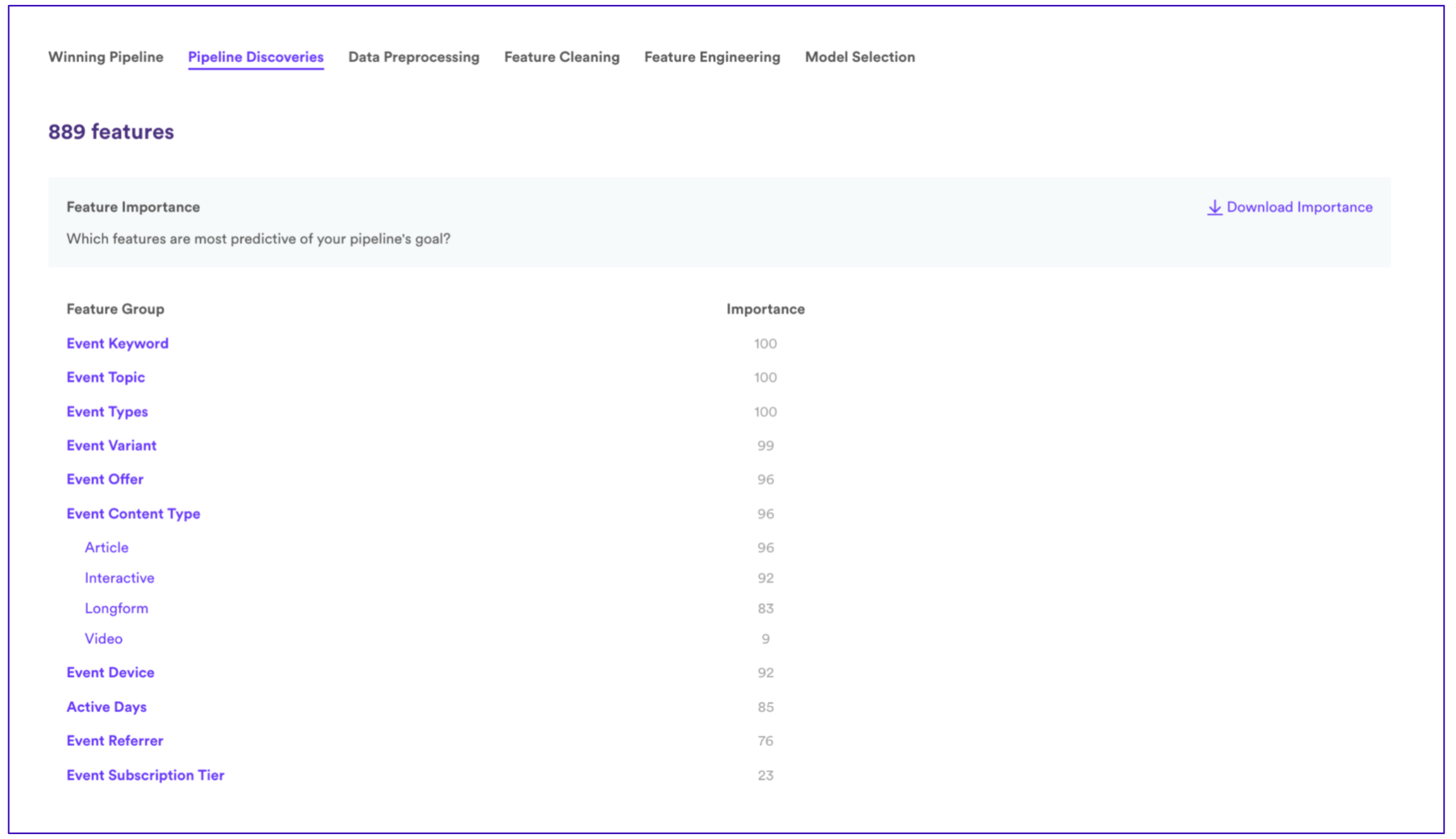
Cortex uses both attributes and behavioral signals and automatically generates behavioral features across multiple windows.
Additional resources on Look-Alike modeling –
- Here is a more detailed discussion of Look-Alike modeling by Vidora product manager Michael Firn
- Here is a Vidora case study examining how seed set size impacts Look-Alike performance
Classification – An Alternative to Look-Alike Modeling
Classification models are a great alternative to Look-Alike models. In Cortex, it’s as easy to build a classification model as it is to build a Look-Alike model. A classification model is provided with both positive examples (the “seed” set mentioned above) of users in your target group, in addition to negative examples of users not in the positive group. The negative examples provide an additional signal which the algorithm can use to determine what is unique about the target group.
One machine learning challenge when using classification models results from unbalanced data-sets. Specifically, there are often many more negative examples than positive examples. For instance, if we are classifying “who is a CEO”, and only 1% of the users are CEOs, then for every one positive example we might have 99 negative examples. This lack of balance, 1% to 99%, can pose challenges to modeling algorithms if not addressed. Cortex has several automated techniques for handling unbalanced data-sets including subs-sampling, weighting, and interpolation algorithms. The ability to handle unbalanced data-sets means that Cortex modelers can easily leverage classification models.
We’ve found that classification models almost always outperform semi-supervised Look-Alike modeling with Cortex for adtech and marketing use cases. However, even with classification modeling, it’s important for model builders to look at the features being used to construct the models and their relative importance to ensure the models are honing in on the correct signals. In general, when building complex models across hundreds of user attributes and thousands of behavioral signals, it’s important to take a peek beneath the hood and understand what the model is using to make decisions.
Click-Based Optimization – Modeling User Intent
Neither, Look-Alike or classification models, as described above, take into account the likelihood of a user to click on an ad or marketing message. The algorithms above could do a great job segmenting users into a segment of “CEOs” or “High Net-Worth Individuals” but the algorithms are not considering the current user intent. In the adtech world, campaigns based on CPC should consider user intent in order to maximize clicks and conversions.
Cortex provides a natural tool for optimizing segments directly for clicks or indeed for optimizing segments for any downstream metric. Future Event models allow a modeler to specify an event to predict for every user. In this case, we might predict the “likelihood of a user clicking on a specific ad campaign”.
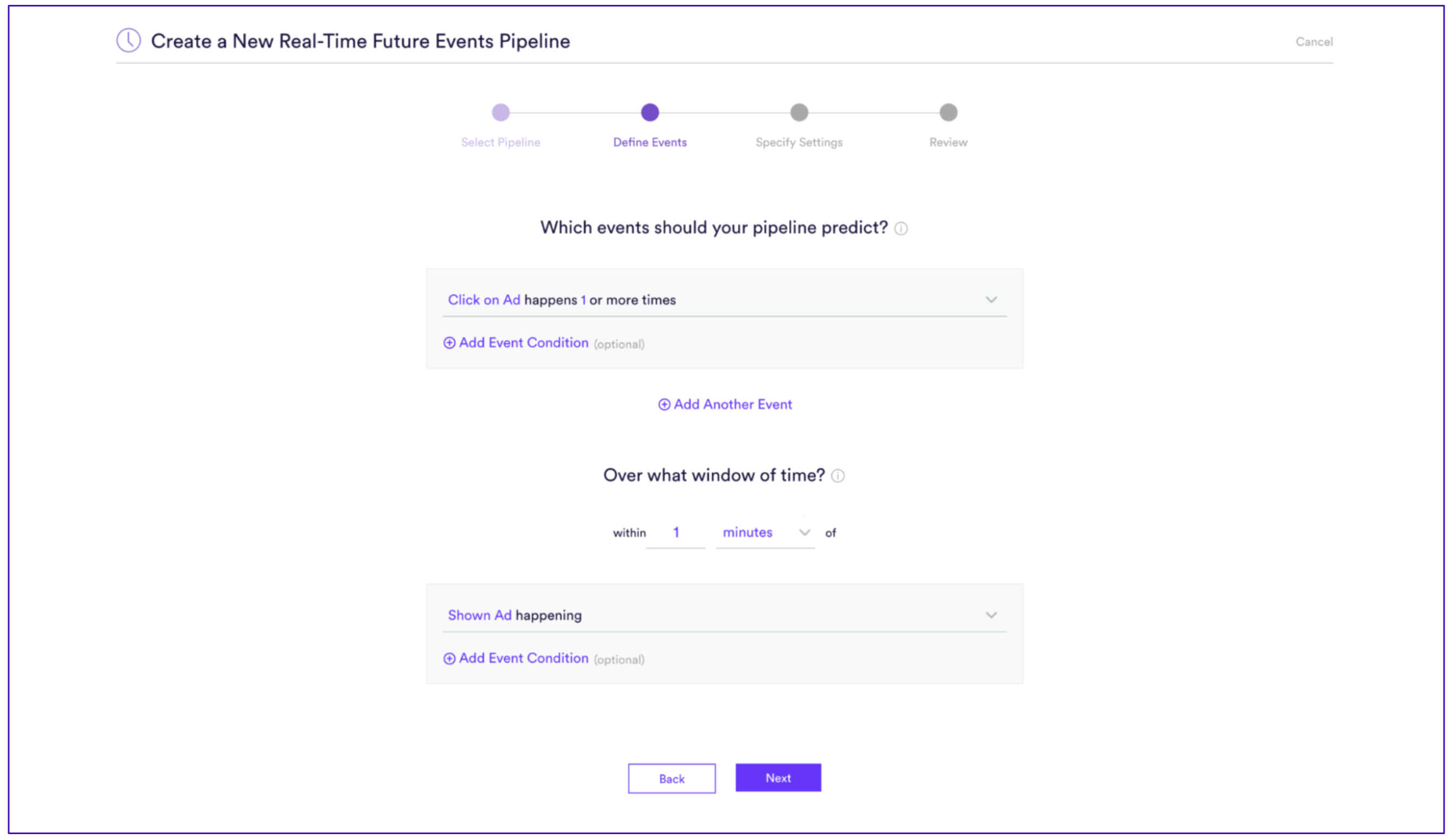
Example of a real-time future events model being created in Cortex that is predicting if a user will click on an ad within one minute of the ad being shown.
Click-based optimization models offer a new type of segmentation more focused on directly optimizing for user intent. Does it work? In this case study we showed that optimizing directly for ad clicks, when compared with a classification model, resulted in a 43% increase in conversions.
In other work we’ve done with media organizations we’ve seen click-through-rate (CTR) be 2-3x higher for campaigns optimized directly for clicks. Note that Cortex also offers real-time tools which allows models to take advantage of in-session behaviors to target users. Here is an overview of the real-time decisioning functionality offered in Cortex in addition to a more technical overview of how Cortex real-time decisioning works.
Uplift Modeling – The Holy Grail of Segmentation
Recall the old adage of “Half the money I spend on advertising is wasted, I just don’t know which half?” (attributed to John Wanamaker). Uplift modeling is a modeling technique which tries to help businesses solve the challenge of wasted advertising spend. Uplift modeling goes beyond looking at user intent and directly models the impact of an ad (user intervention) on a user.
What does this concretely mean? Uplift modeling can tell you how much an ad will increase a user’s likelihood of buying a service. For instance, if you are marketing a CPG, uplift modeling can tell you, for each user uniquely, how much their brand sentiment will increase if they see a particular ad. What this allows advertisers to do is only target users where the cost of running the ad is less than the increased value (uplift) generated by showing it to a user.
We’ve run various uplift campaigns for advertising initiatives and seen increases in positive brand sentiment by 25-50% while targeting dramatically fewer users (75% fewer) when compared with campaigns powered by other modeling techniques. It’s an exciting area for businesses to explore.
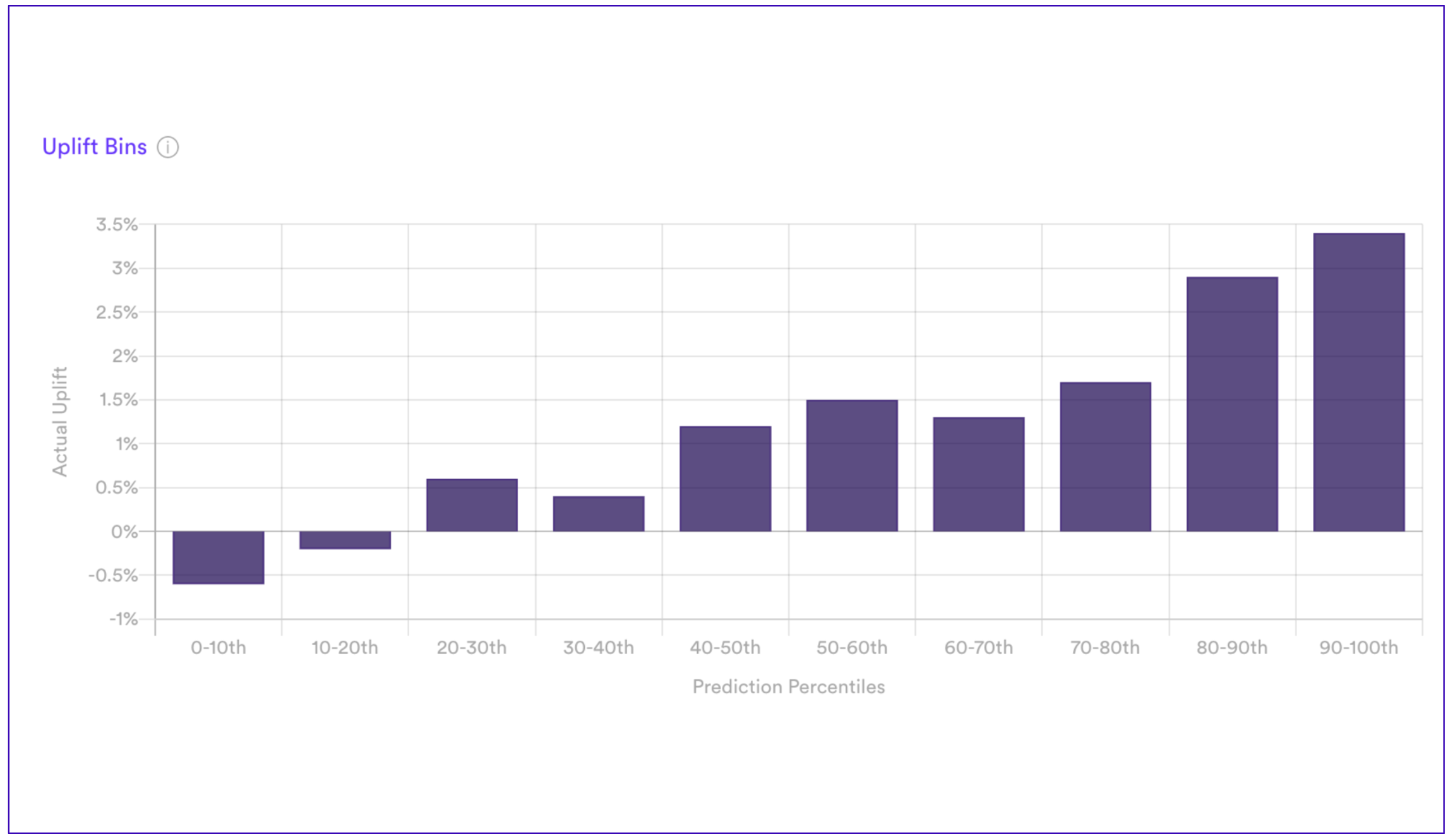
Results from an uplift modeling pipeline shows how some user’s brand sentiment will increase when seeing the ad, while some user’s brand sentiment will decrease.
Conclusion
1st party attribute and behavioral data offer an exciting opportunity for businesses to build out robust user segments to power adtech, marketing, and product use cases. As organizational data continues to increase and be more accessible, it will offer an increasing array of opportunities to take advantage of varying modeling techniques to drive the highest ROI for businesses.


