How Can We Help?
Real-Time vs. Batch Pipelines
Because Cortex processes continuous streams of data, your Machine Learning pipelines can be configured to refresh over time based on new data. This means that your pipelines quickly adapt to new users and changing data in order to return the most value to your business.
There are two pipeline setups that you can use to keep predictions up-to-date: Batch inference or Real-Time inference. In this article, we’ll provide an overview of each method and discuss how and when they might be useful for your business.
Batch vs. Real-Time Inference
Once a Machine Learning model has been trained, the final step of the ML Pipeline involves using this model to make predictions on an ongoing basis. This step is known as Prediction Generation, or Inference.
There are two ways to set up ongoing inference for a pipeline in Cortex:
- Batch – A pipeline configured for Batch inference will automatically re-generate fresh predictions on a recurring schedule (e.g. daily, weekly, or monthly). All users included in the pipeline will receive a prediction at the time of refresh.
- Real-Time – A pipeline configured for Real-Time inference will re-generate fresh predictions on-demand as users browse your site. When you request a real-time prediction for a given user, that prediction will incorporate the most up-to-date information, including behavior from the current browsing session.
Whether or not you use batch or real-time inference depends on how you plan to deploy the pipeline:
- For offline use cases (such as a recurring broadcast email campaign), your pipeline should make batch predictions. These predictions are generated all at once, so they can easily be refreshed and exported in bulk on the same schedule as your campaign.
- Online use cases (such as dynamic next-best-action targeting on your website or app) can leverage either batch or real-time predictions (accessible via API). However, real-time predictions carry a few key advantages in this setting: (1) predictions are always up-to-date at the time they are used for decision-making, and (2) predictions can be made for first-time users.
Choosing an Inference Mode in Cortex
Batch inference is available for all of Cortex’s pipeline types, while real-time inference is available for Future Events and Uplift pipelines. To select your inference mode, toggle between “Batch” and “Real-Time” when choosing which type of pipeline you’d like to create in Cortex.
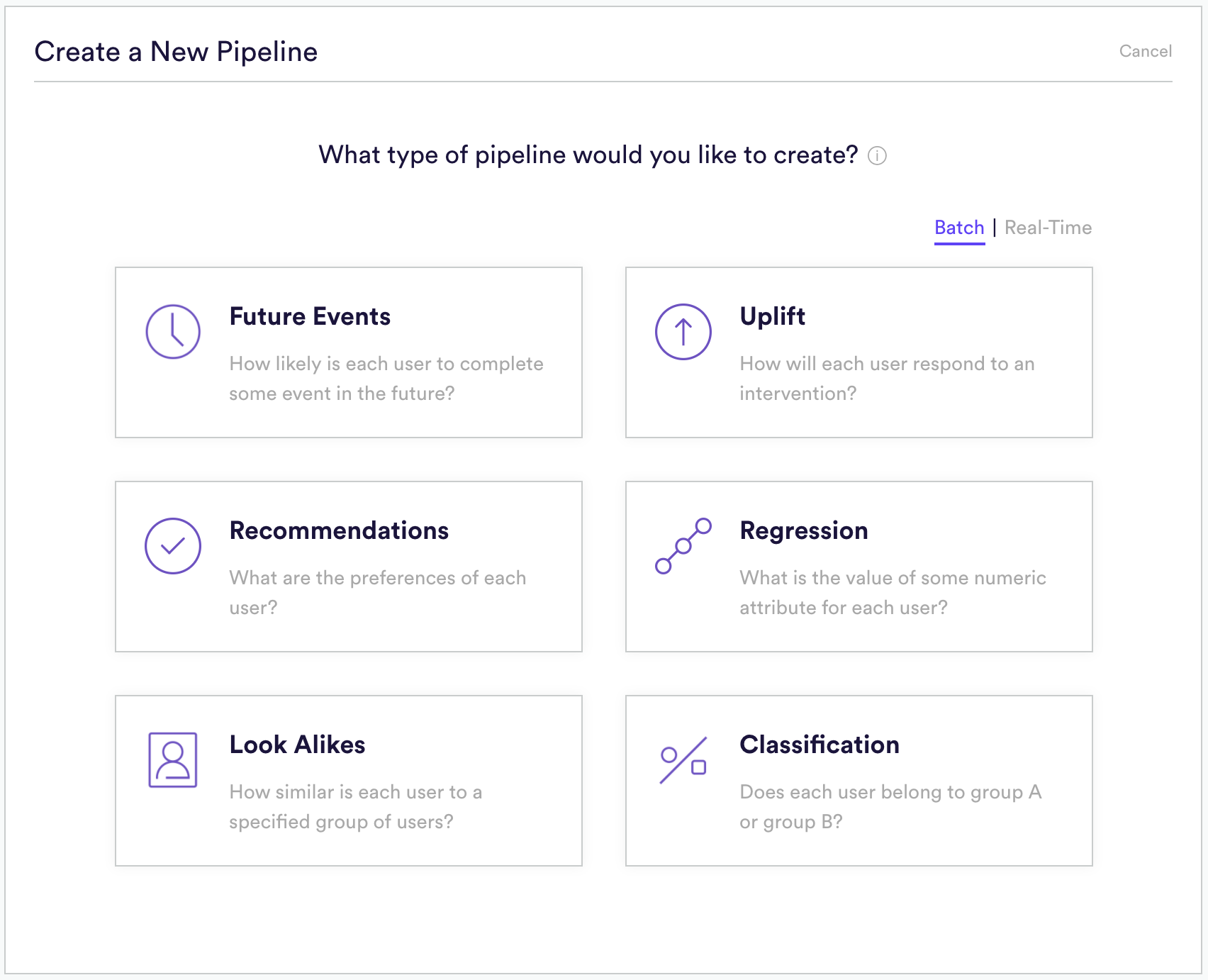
The way in which you set up, access, and deploy your pipeline is slightly different depending on which inference mode you choose. See below for a comparison of functionality for each mode.
Creating Your Pipeline
Creating a real-time pipeline is overall very similar to creating a batch pipeline. One notable difference for Uplift involves how you specify the interventions whose impact your pipeline should consider. A Batch Uplift pipeline requires you to run a random A/B test with your interventions, and upload the results. A Real-Time Uplift pipeline, on the other hand, automates this A/B test via explore/exploit functionality. Instead, simply specify the events which represent a user receiving your treatment and control interventions.
Click here for step-by-step instructions on how to build a Batch or Real-Time Uplift pipeline. Click here for step-by-step instructions on how to build a Batch or Real-Time Future Events pipeline.
Scheduling Your Pipeline
When creating a Batch pipeline, you’ll specify the schedule that your pipeline should follow when generating new predictions. Options include daily, weekly, or monthly. Because Real-Time pipelines generate predictions on-demand, they require no such schedule.
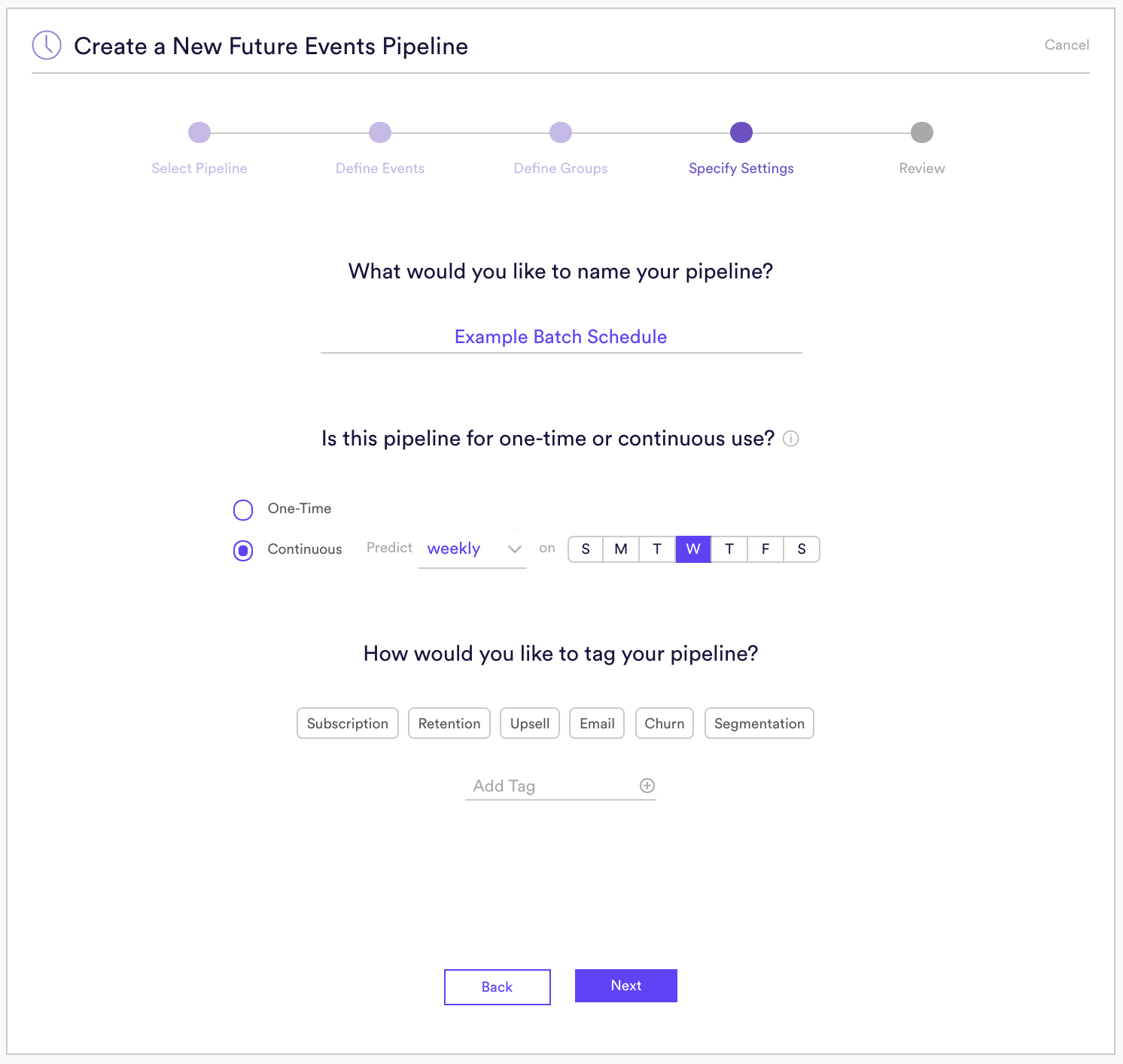
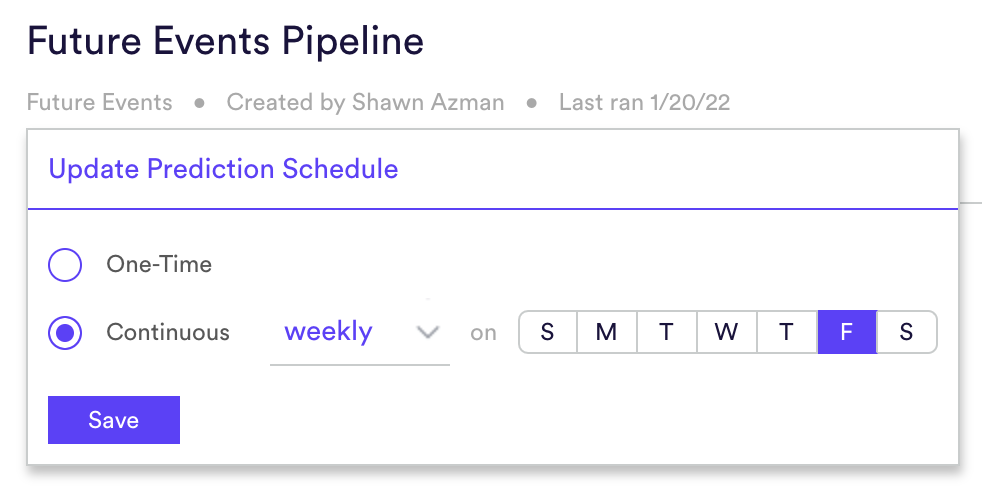
You also have the ability to update the Pipeline Schedule after the pipeline has finished training. Simply navigate to the Pipeline Results page, and underneath the Pipeline Name you will see the option to Update Schedule. There you can change the schedule frequency.
Training Your Pipeline
Batch pipelines use historical data only when generating predictions. This means that as soon as you create a Batch pipeline, it will immediately access that historical data and begin training.
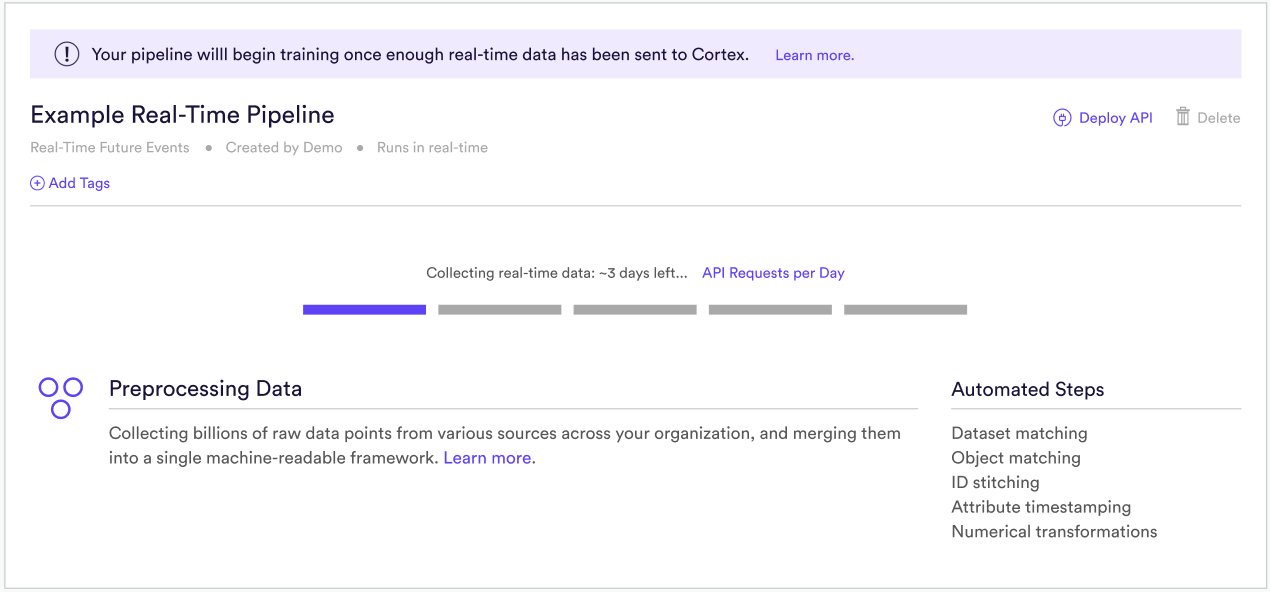
A Real-Time pipeline, on the other hand, must gather additional data from users’ current browsing session. When you create a Real-Time pipeline, it will enter an initial “Data Collection Period” before training is ready to begin. While in the “Data Collection Period”, your pipeline will be in one of two states:
(A) Waiting for real-time data. This status indicates that your pipeline has been created, but no real-time data has been received. To begin sending this data, (1) deploy your pipeline to a new or existing Decision Project, and (2) implement the JavaScript SDK’s Behavioral and Decision modules so that your pipeline has real-time access to in-session user behaviors, and in-session treatment decisions (e.g. “this user was shown a paywall”). Note that you may use the Check Your Events developer tool in Cortex to verify that the events you send through the SDK are in fact being received by Cortex.
(2) Collecting real-time data. This status indicates that you’ve begun sending real-time data, but not enough to begin training. Once enough data has been collected in order to generate high-quality predictions, your pipeline will automatically begin training. Note that you may view the API Overview section of your Cortex account in order to monitor how many SDK requests have been made on a daily basis.
Deploying Your Pipeline
A Batch pipeline can be deployed in one of two ways: (1) use a Prediction Export to schedule a recurring delivery a batch of predictions to a custom third-party destination (for offline use cases), or (2) create a Decision Project to power decisions which can be accessed via the Decision SDK (for onsite use cases).
A Real-Time pipeline has no batch predictions to export all at once. Instead, a Real-Time pipeline can be deployed onsite by creating a Decision Project and accessing results via the Decision SDK. This enables you to dynamically determine in real-time which experience should be served to each user in order to optimize your business.
Related Links
- How to Build a Future Events Pipeline
- How to Build an Uplift Pipeline
- How to Build a Look Alike Pipeline
- How to Build a Classification Pipeline
- How to Build a Regression Pipeline
- How to Build a Recommendations Pipeline
Still have questions? Reach out to support@mparticle.com for more info!