How Can We Help?
Predict Fraudulent Property Listings
In this use case example, we will be walking through how to predict fraudulent real estate property listings using a Machine Learning Pipeline called Classification. Specifically, we’ll cover how to predict each new property listing’s probability, on a scale from 0-100%, of being a fraudulent listing based on a list of previous listings that were known to be fraudulent as well as listings known to not be fraudulent.
What data do I need for this prediction?
This prediction will answer the question: how likely is each new property listing of being fraudulent, based on a known list of properties that were fraudulent and others that were known to be non-fraudulent. This information is uploaded to the Cortex as a CSV of Property IDs and a 1 or 0 value based on if that property was known to be fraudulent or not.
While the list of Property IDs and Labels is the only information required when setting up our Classification pipeline, additional information about these properties is needed in order to make accurate predictions. This information is used to build features for our pipeline:
- Property Attributes: this represents information about the property listing itself. Information could include asking price, size, location, etc.
- User Behaviors: with listings being available to view an interact with online, any events and behaviors tracked to this property can be used in the prediction. These events can be a user viewing the listing, favoriting, contacting the owner or agent, etc.
How do I predict the Likelihood a Property Listing is Fraudulent?
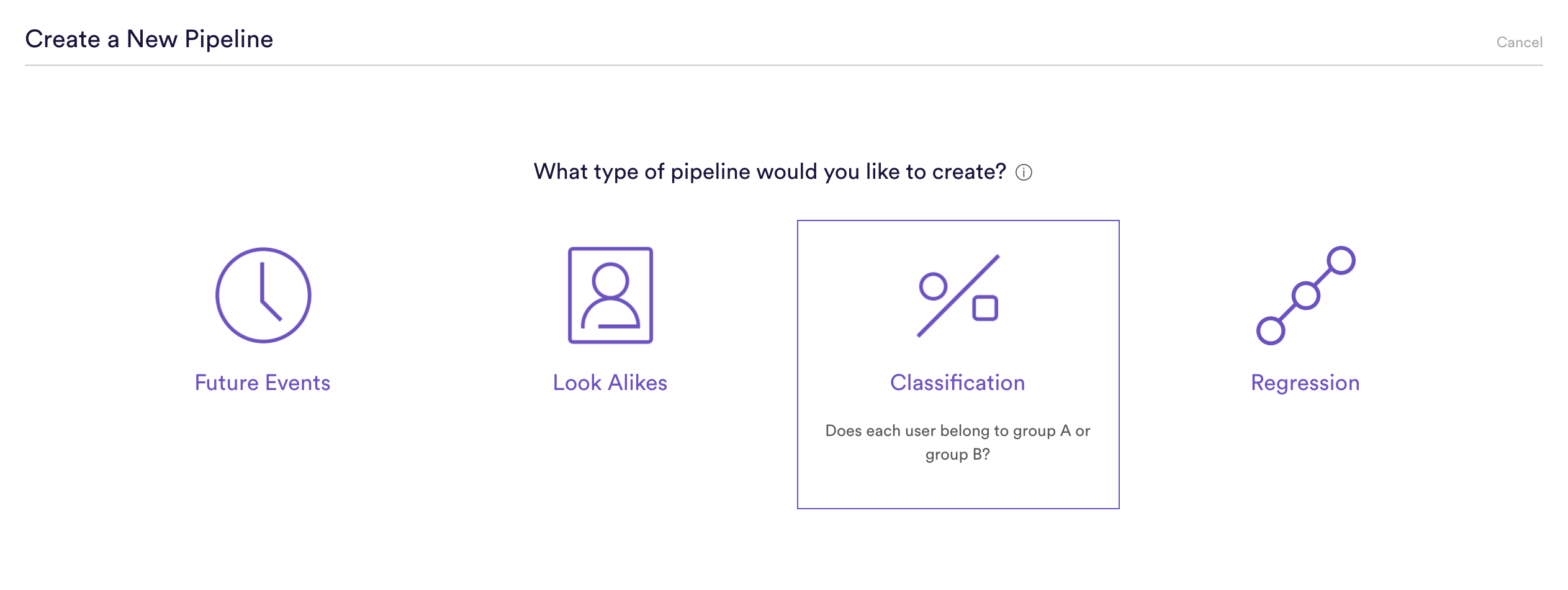
Step 1: Choose Pipeline Type
Select ‘Create New Pipeline’ from your Cortex account, and choose the Classification pipeline type.
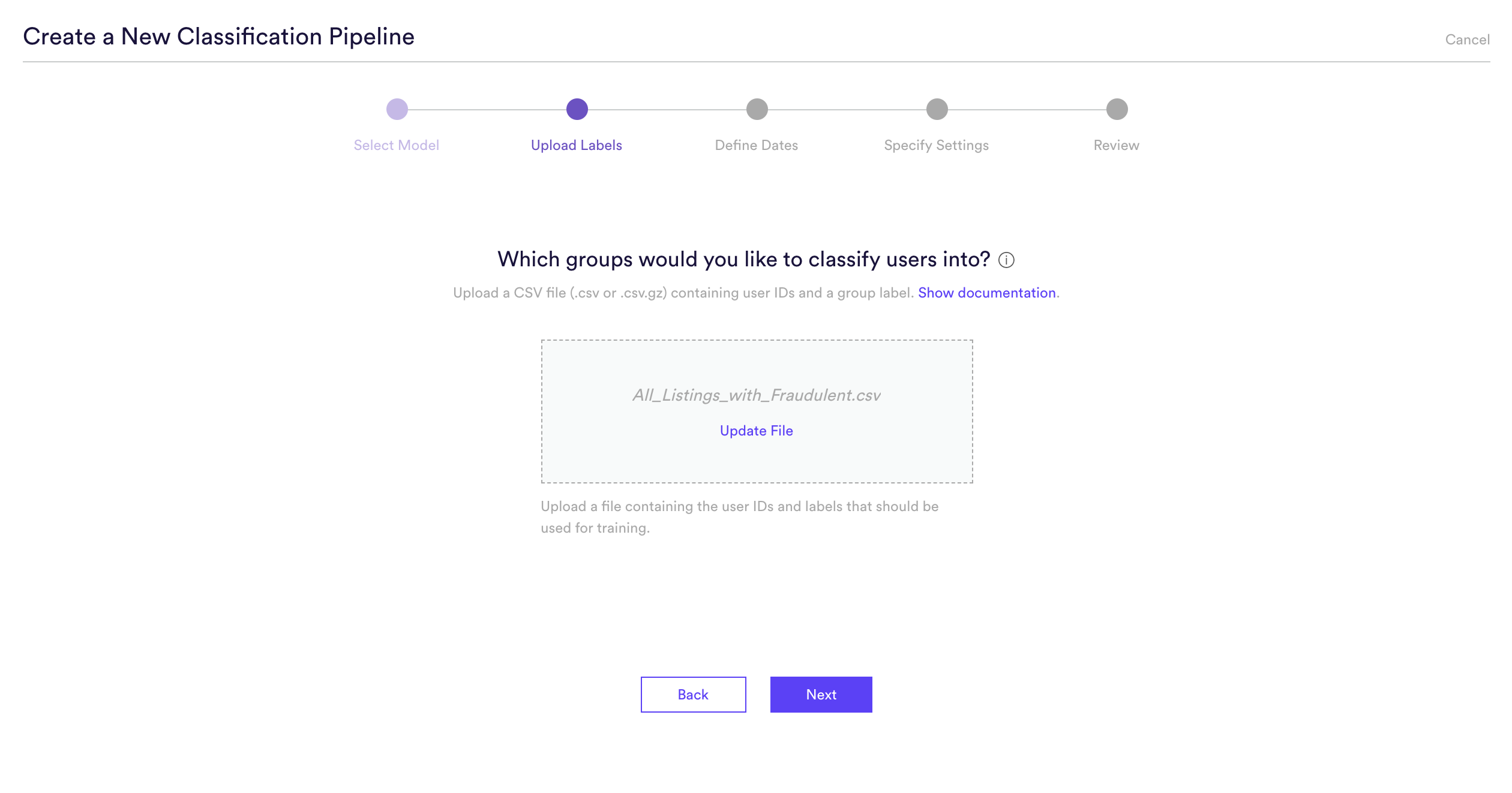
Step 2: Upload Sets
This is where we upload our list of Property IDs representing known fraudulent and non-fraudulent listings. This file should be a .csv or or .csv.gz file, consisting of two columns: id and label. The value of 1 will represent positive labels of fraudulent listings, and the value of 0 will represent negative labels, or in this case non-fraudulent listings.
| id | label |
| abc123 | 1 |
| xyz987 | 0 |
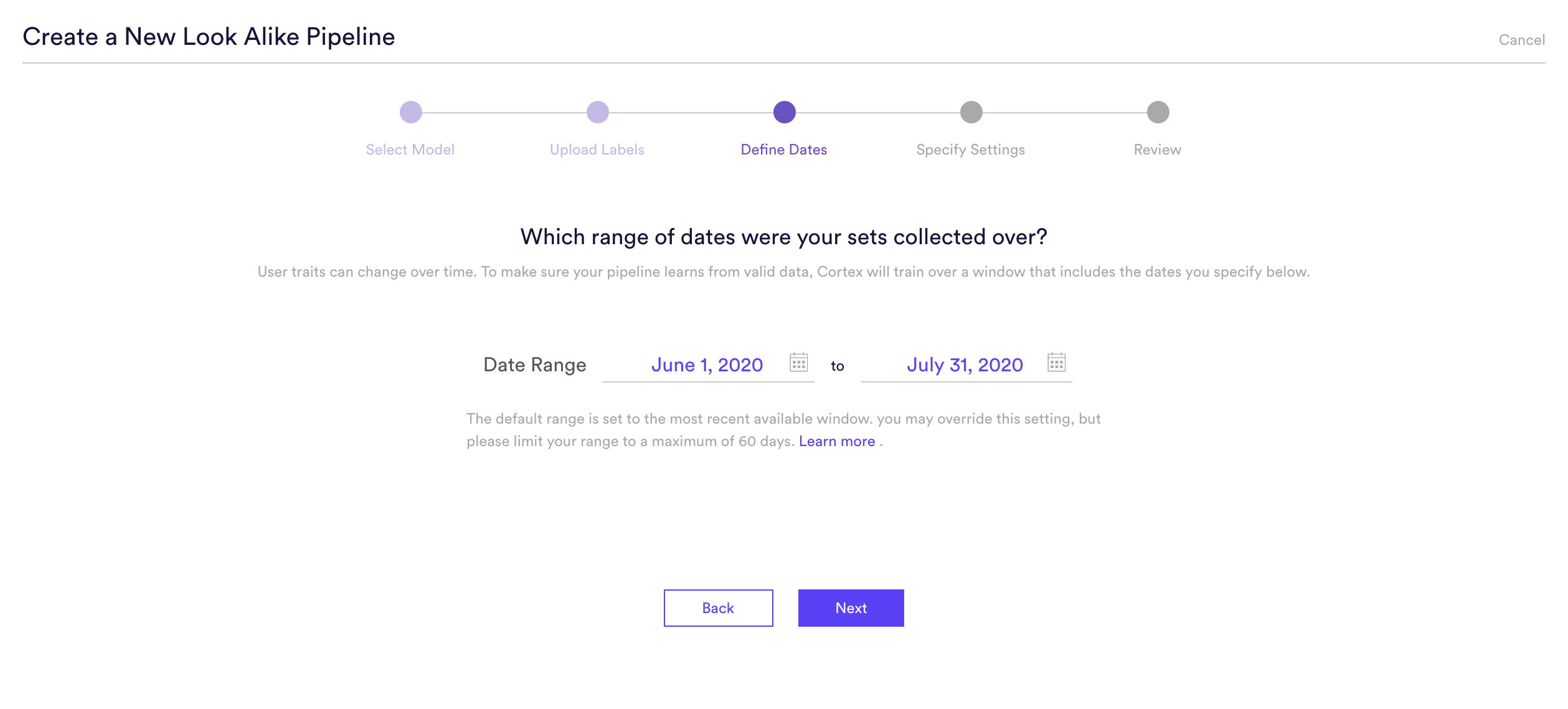
Step 3: Define Dates
Patterns can change over time, therefore it is important to specify the date range in which it was known that these new listings were fraudulent. This date range allows the Machine Learning Pipeline to learn from that data and listings specifically from that period.
In this example we are choosing the default range, but this can be any date range from which the new listings were collected.
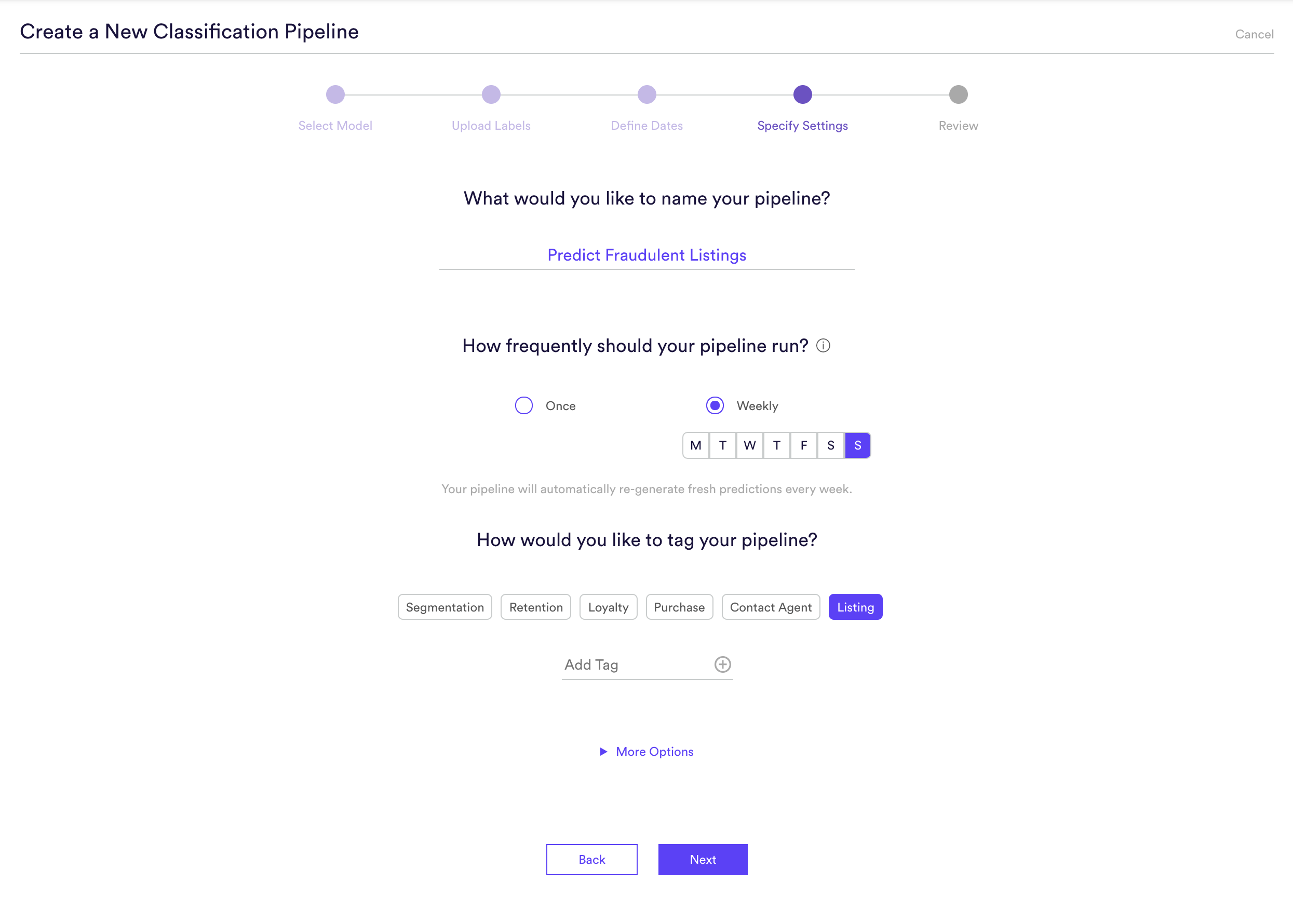
Step 4: Specify Settings
In this step, we will name our Pipeline ‘Predict Fraudulent Listings’, have it rerun weekly on Sundays, and tag the pipeline with the ‘Listing’ tag. Setting a weekly schedule means that your pipeline will use the latest available data to re-generate up-to-date predictions on a weekly basis.
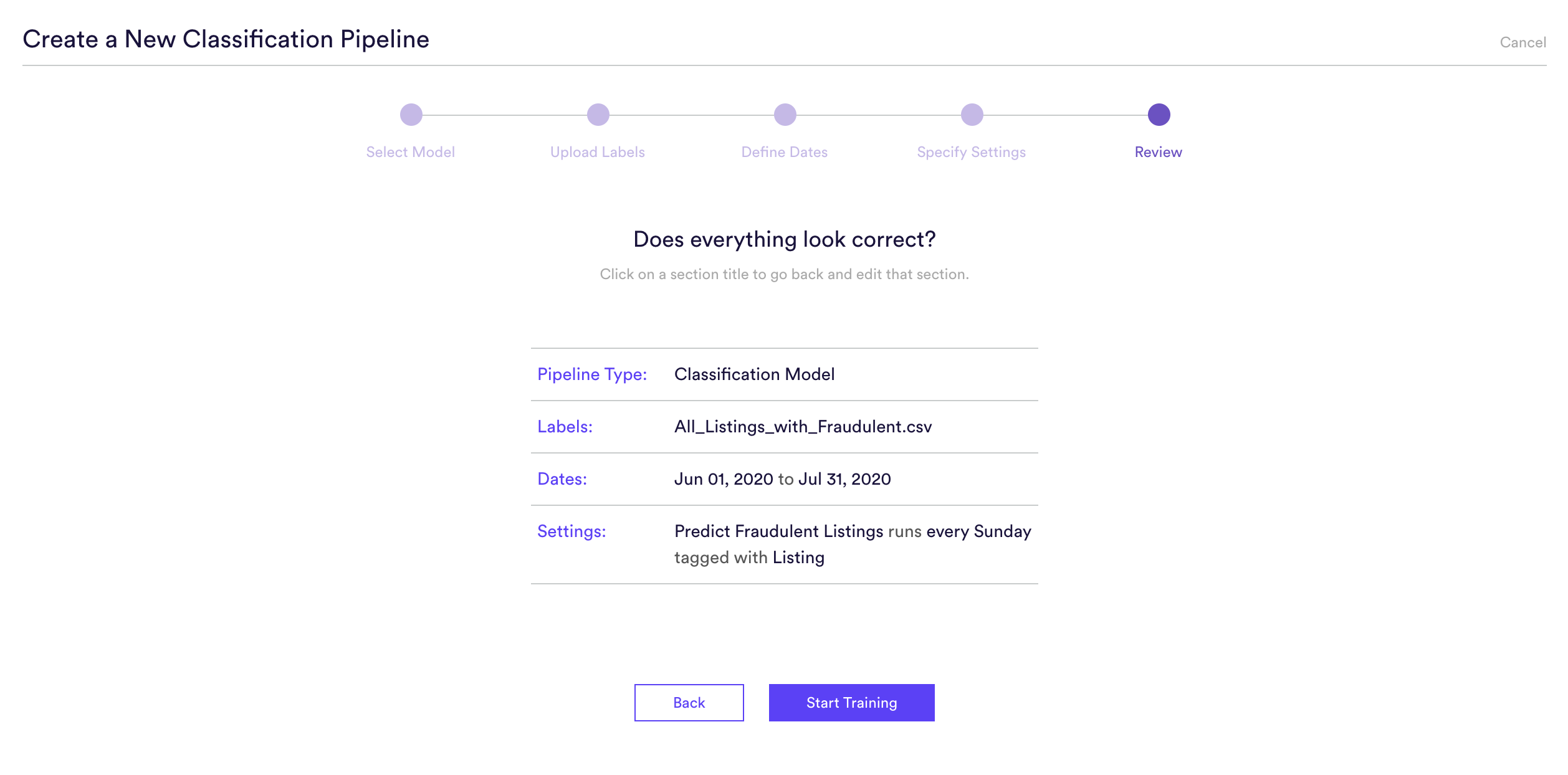
Step 5: Review
The final step is to review your pipeline and ensure all settings look accurate! If anything needs updated, simply go ‘Back’ in the workflow and update any step. Otherwise, click ‘Start Training’ and sit back while Cortex generates the predictions.
Step 6: Update Labels Over Time (Optional)
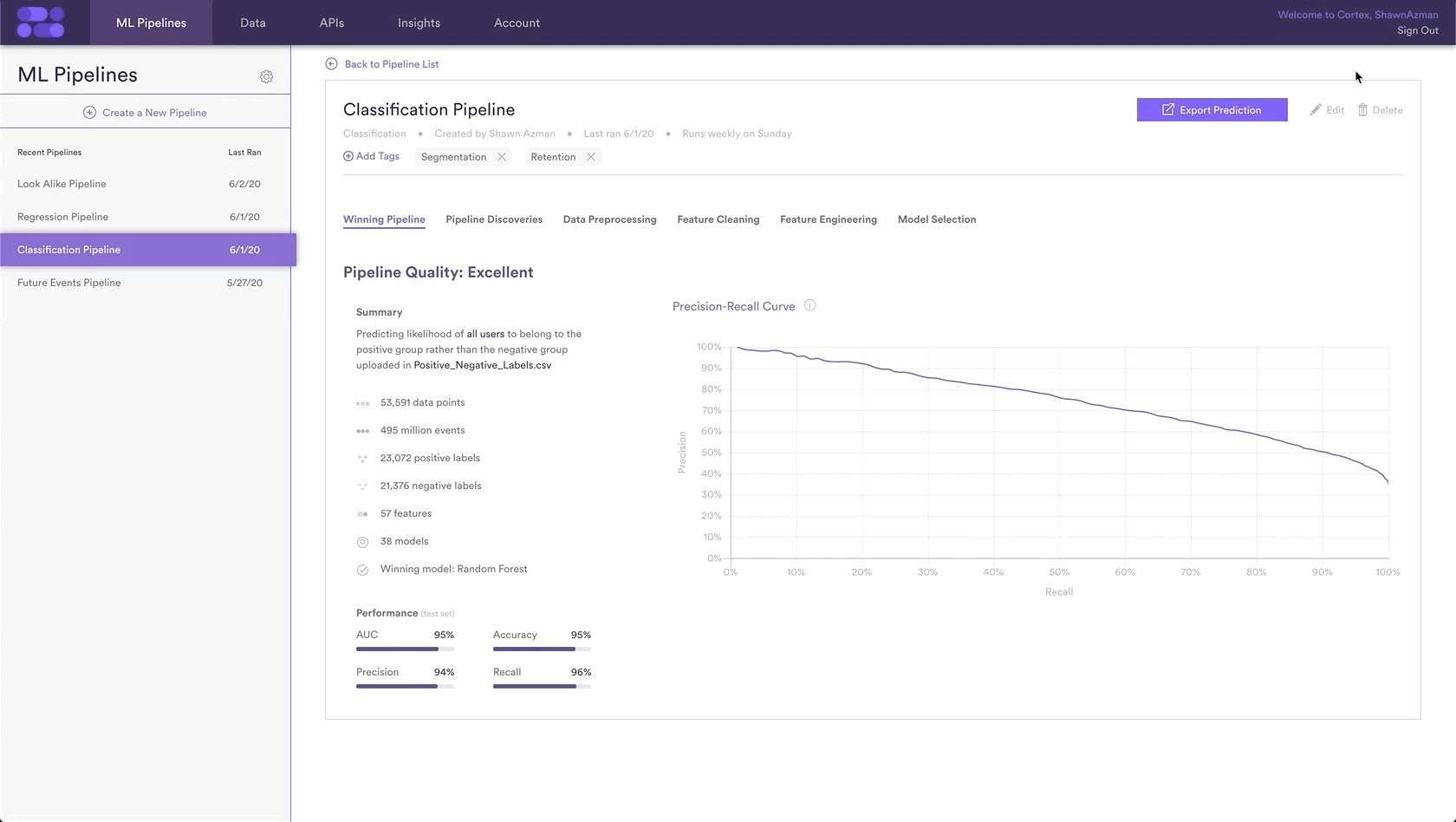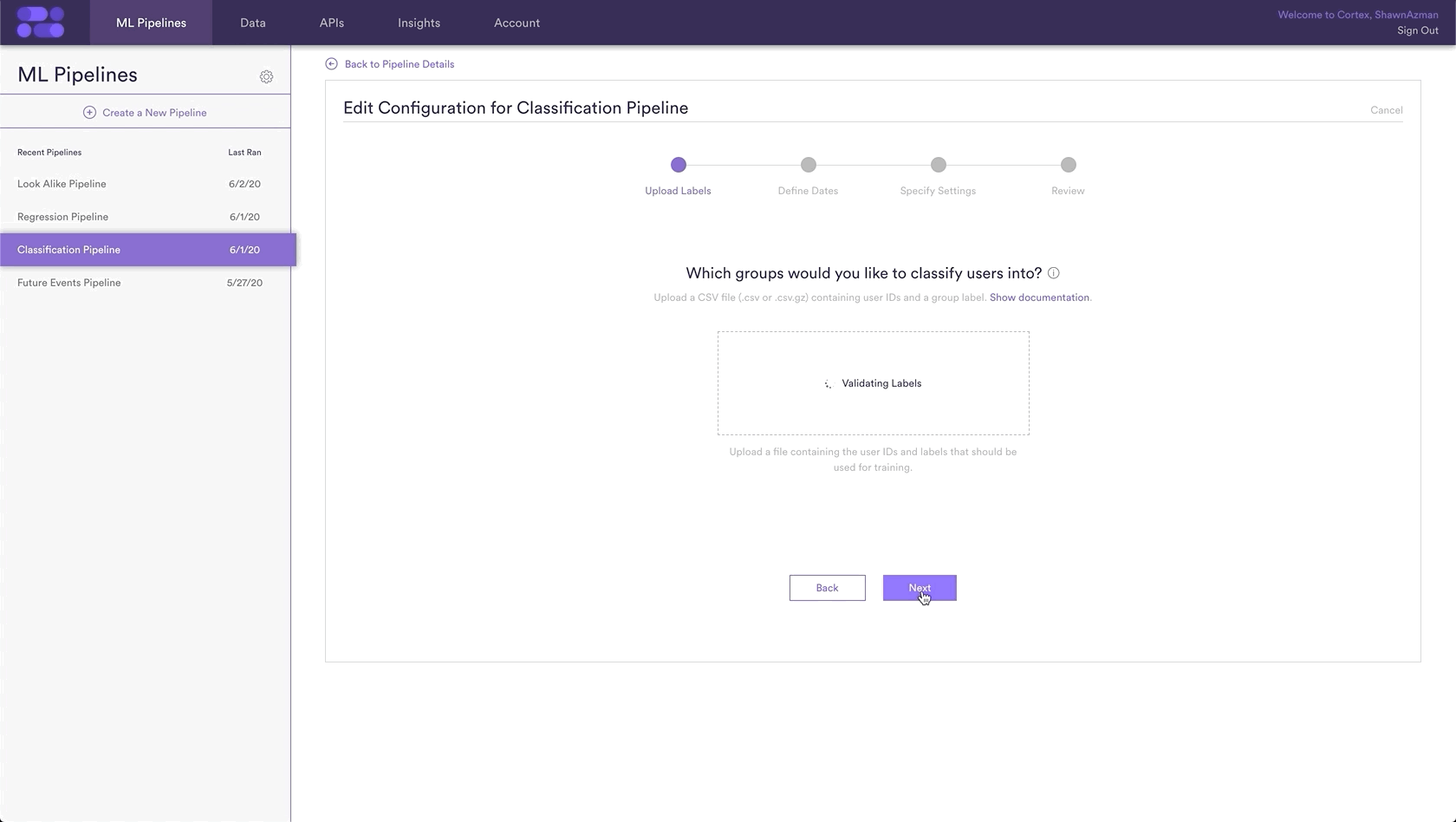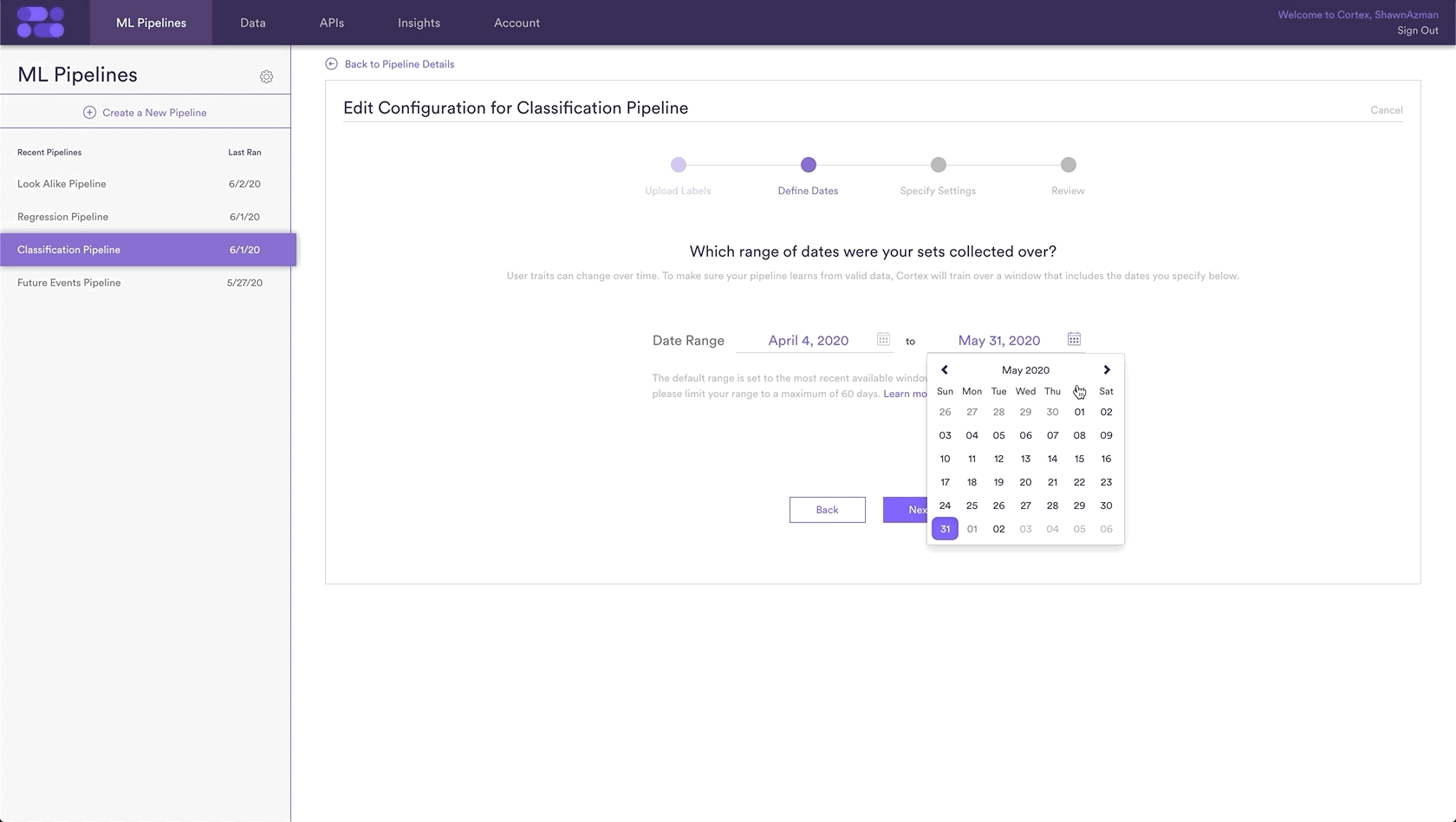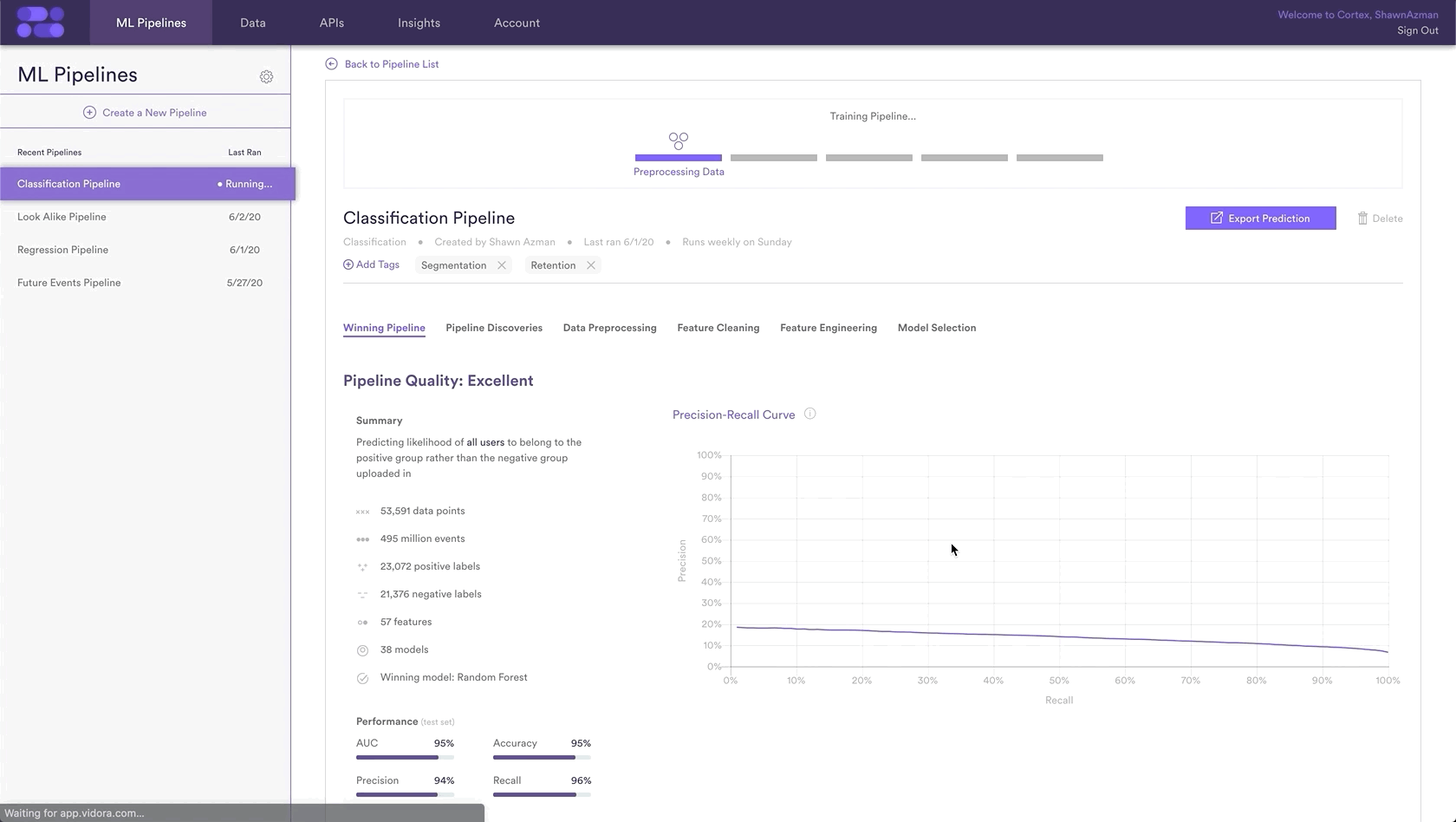
If you’re collecting new User IDs of known <Attribute_Plural> and <Not_Attribute> over time, you can import these extra labels into Cortex so that your pipelines are always learning from the most recent information. To upload new labels, hit the “Edit” button on your pipeline (next to “Export Predictions”).
Related Links
- Classification Performance
- How to Build a Look Alike Pipeline
- How to Build a Regression Pipeline
- How to Build a Future Events Pipeline
Still have questions? Reach out to support@mparticle.com for more info!