How Can We Help?
Cortex Overview
mParticle Cortex is the world’s leading platform for businesses looking to build Machine Learning powered decisioning atop large-scale customer data. One of the most valuable ways any enterprise organization can use ML is to power an automated decision engine which delivers a continuous stream of ROI. With Cortex, any organization can quickly create complex Machine Learning (ML) pipelines, and deploy these pipelines for automated decision making across their product, marketing, and ad-tech initiatives.
Cortex’s decisioning functionality is enabled by three interconnected layers: the Data Layer, the ML Pipelines Layer, and the Decision Layer. This document provides a general overview of each one.

Data Layer
Cortex’s Data Layer continuously ingests streams of raw data and processes it into tabular datasets well suited for Machine Learning. Cortex is both seamlessly integrated with other platforms in the data ecosystem, and fully equipped with its own set of REST APIs, enabling a variety of mechanisms to ship your data in and out of the platform.
ML Pipelines Layer
Cortex’s ML Pipelines Layer makes it easy to build and analyze complex ML models in an intuitive, no-code interface. The term “ML Pipeline” refers to a multi-step framework which automatically cleans your ingested data, transforms it into a machine-readable form, trains a model, and generates predictions — all on a continuous basis. By automating the most tedious steps in the process, Cortex makes ML fast, explainable, and production-ready for anyone in your organization.
The ML Pipelines Layer offers several types of machine learning models for predicting future behavior, campaign uplift, user attributes, personalized recommendations, and more. These pipelines can be set to generate fresh results in real-time, ensuring that your automated decisions are always based on the most up-to-date information. Cortex also provides insight into your pipelines’ performance and features, helping you build confidence in the results before going live.
Decision Layer
At their core, ML Pipelines provide information – What will this user do? How will this user respond to this campaign? What is this user’s age range?
But even the most accurate ML Pipelines are only useful if they’re driving real value for your business. Cortex’s Decision Layer is designed to bring this value to life, making it easy to deploy your pipelines for automated decision-making at scale.
The Decision Layer provides tools for translating predictions into concrete actions that your business should take in order to achieve a goal. For example, an ML Pipeline might predict each customer’s likelihood to subscribe within the next week. But if the real goal is to maximize subscriptions, what is the best way to act upon this information? Who should be targeted with an email campaign? Who should get a discount code? Who should be left alone? Cortex’s Decision layer helps you answer these questions while also simplifying the operational process of making real-time decisions at scale.
Typical Cortex Workflow
Cortex can help businesses optimize user journeys both offline (e.g. outbound marketing) and online (e.g. onsite promotion). This section provides a high-level overview of the typical workflow required for each. Follow the embedded links for more information about how to accomplish specific tasks.
Online Decisions

Step 1: Set up Data Sources
Integrate Cortex with your existing third-party data sources, so that this information can be used to build ML Pipelines. The types of data supported by Cortex fall into five categories: events, attributes, subscriptions, items, and ID mappings.
Step 2: Build ML Pipelines
Next, identify ML pipelines that will help inform your goal, and build those pipelines quickly and easily in Cortex’s no-code interface. For example, if your goal is to maximize subscriptions by showing one of two onsite banner promotions, you may wish to build real-time Future Events pipelines to predict each user’s likelihood to subscribe if they were shown each promotion.
Once your pipeline has been built, Cortex makes it easy to unpack the results so that you can understand (a) the accuracy of its predictions, and (b) the types of features that it relied on in order to generate these predictions.
Step 3: Deploy Decisions
Create a Decision Project by specifying the rule that Cortex should use when making decisions about each user’s onsite journey. These rules are based on the output of one or more ML Pipelines, and can be tested and modified over time in order to generate the most possible business value. For example, you might specify a rule such as the following –
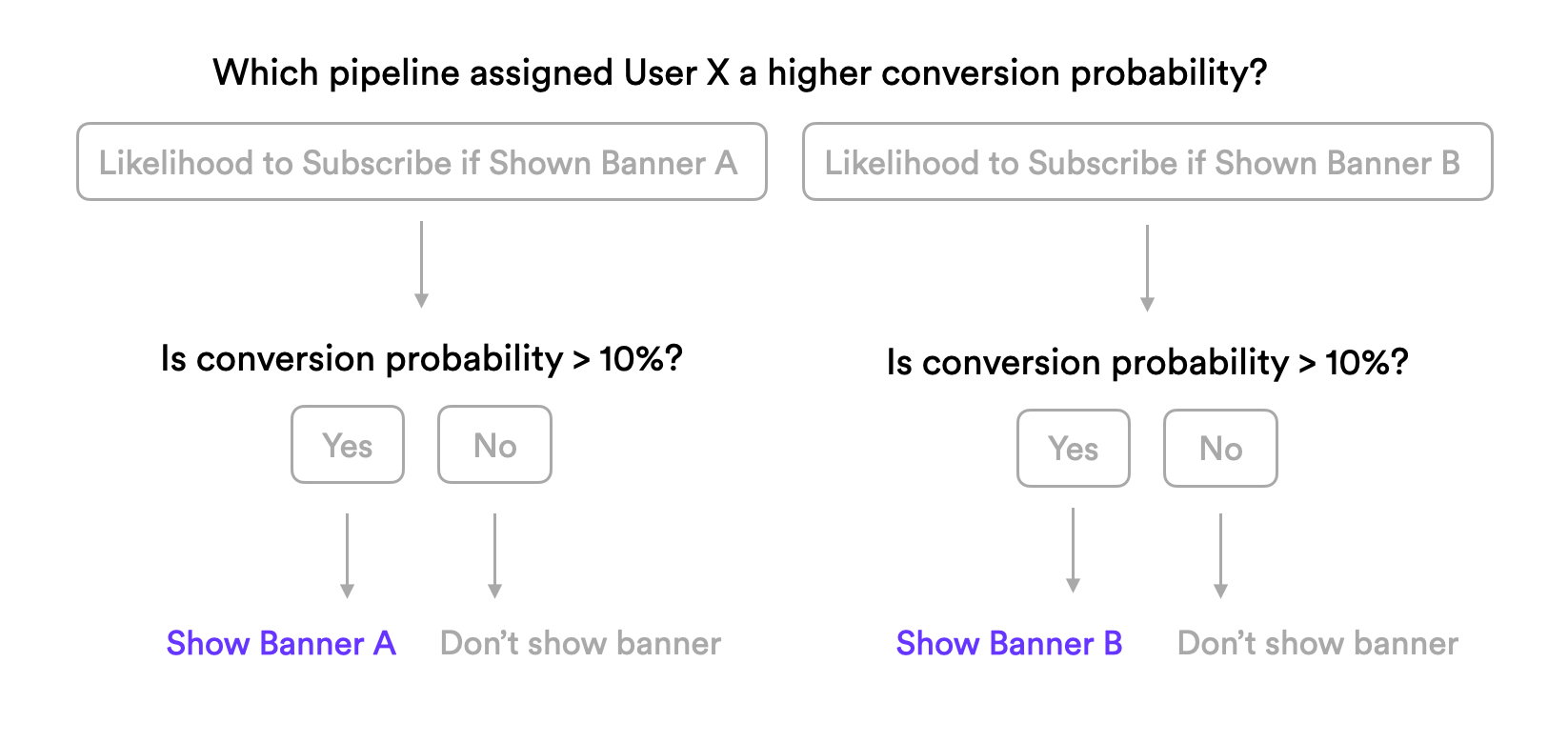
Once you’ve created your Decision Project, deploy it live onsite by integrating Cortex’s JavaScript Decision SDK. The SDK enables you to request a real-time decision for each user as they are browsing your site.
Offline Decisions

Step 1: Set up Data Sources and Destinations
Integrate Cortex with your existing third-party data sources, so that this information can be used to build ML Pipelines. The types of data supported by Cortex fall into five categories: events, attributes, subscriptions, items, and ID mappings.
Next, integrate third-party destinations to which results should be delivered. Once you’ve built ML Pipelines, you can set up a recurring export to ship fresh audience segments to these destinations in order to power marketing campaigns such as outbound emails.
Step 2: Build ML Pipelines
Next, identify ML pipelines that will help inform your goal, and build those pipelines quickly and easily in Cortex’s no-code interface. For example, if your goal is to maximize transactions through a promotional email campaign which includes a coupon code, you may wish to build an Uplift pipeline which predicts how the discount will impact each user’s likelihood to purchase.
Once your pipeline has been built, Cortex makes it easy to unpack the results so that you can understand (a) the accuracy of its predictions, and (b) the types of features that it relied on in order to generate these predictions.
Step 3: Export Predictions
Prediction Exports allow you to make decisions about which users to target based on your pipeline’s predictions. For example, the below cohorts can be refreshed and exported anew every time a pipeline runs.
- “Export IDs for the top 1,000 users by predicted purchase probability”
- “Export IDs for any user with greater than 80% churn probability”
- “Export IDs for the top 10% of users by predicted subscription probability”
The results from a Prediction Export can be downloaded to a CSV file from Cortex or programmatically. If you’ve set up a third-party integration, you may also configure your Export to send results to a third-party destination.
Related Links
Still have questions? Reach out to support@mparticle.com for more info!