
At Vidora, we’ve designed Cortex to be flexible when it comes to data ingestion. Data ingestion is the process of transporting data from one or more data source into a storage medium. With our new Cortex update, integrating data feeds to build better machine learning pipelines is easier than ever.
Cortex enables businesses to build, monitor, and integrate machine learning pipelines throughout their business. These pipelines ingest data on an ongoing basis and transform this data into various machine learning pipelines such as Uplift Models, Predictions, Look-alike Models, and Personalization experiences.
When it comes to ingesting data, we provide a variety of mechanisms. The three main methods our customers use to send data into Cortex are through APIs, data lakes/data warehouses, and direct partner integrations. Displayed in the chart below are an example of each method of sending data into Cortex.

Over the past few months, we’ve noticed an accelerating trend across our customers who are increasingly centralizing all their data into data lakes and data warehouses. Data lakes facilitate the storage of data while data warehousing is the process of collecting and managing data from various sources. As a result, we’ve expanded our data ingestion capabilities to make it easier for users to add new sources of data with a particular focus on data lakes and data warehouses.

Examples of data lakes and partner integrations that are available in Cortex
How it Works
Cortex supports a variety of different data sources including behavioral events, user metadata, item metadata, and ID mapping tables. Once connected to Cortex, these data sources provide a consistent source of new data ensuring the machine learning pipelines reflect the latest data. In addition, Cortex provides ingestion monitoring capabilities to highlight any breakages.
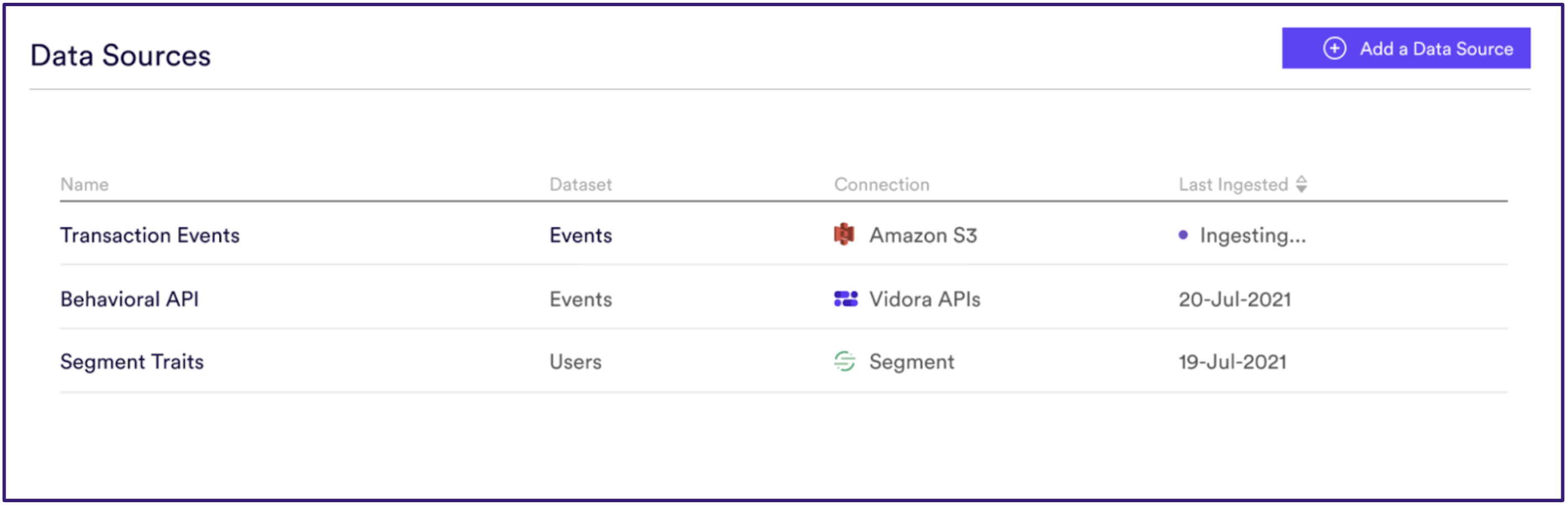
Here is a screenshot from an account that is continuously loading data across Amazon S3, Vidora real-time Behavioral APIs, and Twilio Segment
Get Started Today!
We are super excited with this latest update. Our customers will now have even more flexibility when it comes to sending new sources of data to Cortex. We expect to see more powerful and performant machine learning pipelines and new automation opportunities across businesses!
If you have any questions or would like to take advantage of these new data ingestion capabilities – please feel free to reach out to us at info@vidora.com!


