How Can We Help?
Amazon S3
A Data Source in Cortex represents an integration between your Cortex account and a third-party platform used for enterprise data storage. Once your source is connected, data will regularly flow into Cortex where it can be used to build Machine Learning pipelines.
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. In this guide, we’ll walk through how to connect Amazon S3 as a Data Source within your Cortex account.
Connecting an Amazon S3 Data Source
To connect your Cortex account to an Amazon S3 bucket, create a Data Source in Cortex by following the steps below. Each Data Source must be associated with a single schema, so if your S3 bucket contains multiple distinct datasets that you’d like to send to Cortex, you should create a separate Data Source for each one.
Step 1: Select Platform
First navigate to the Data Sources area of the Data tab in Cortex, and select the “Amazon S3” icon from the list of available third-party platforms.
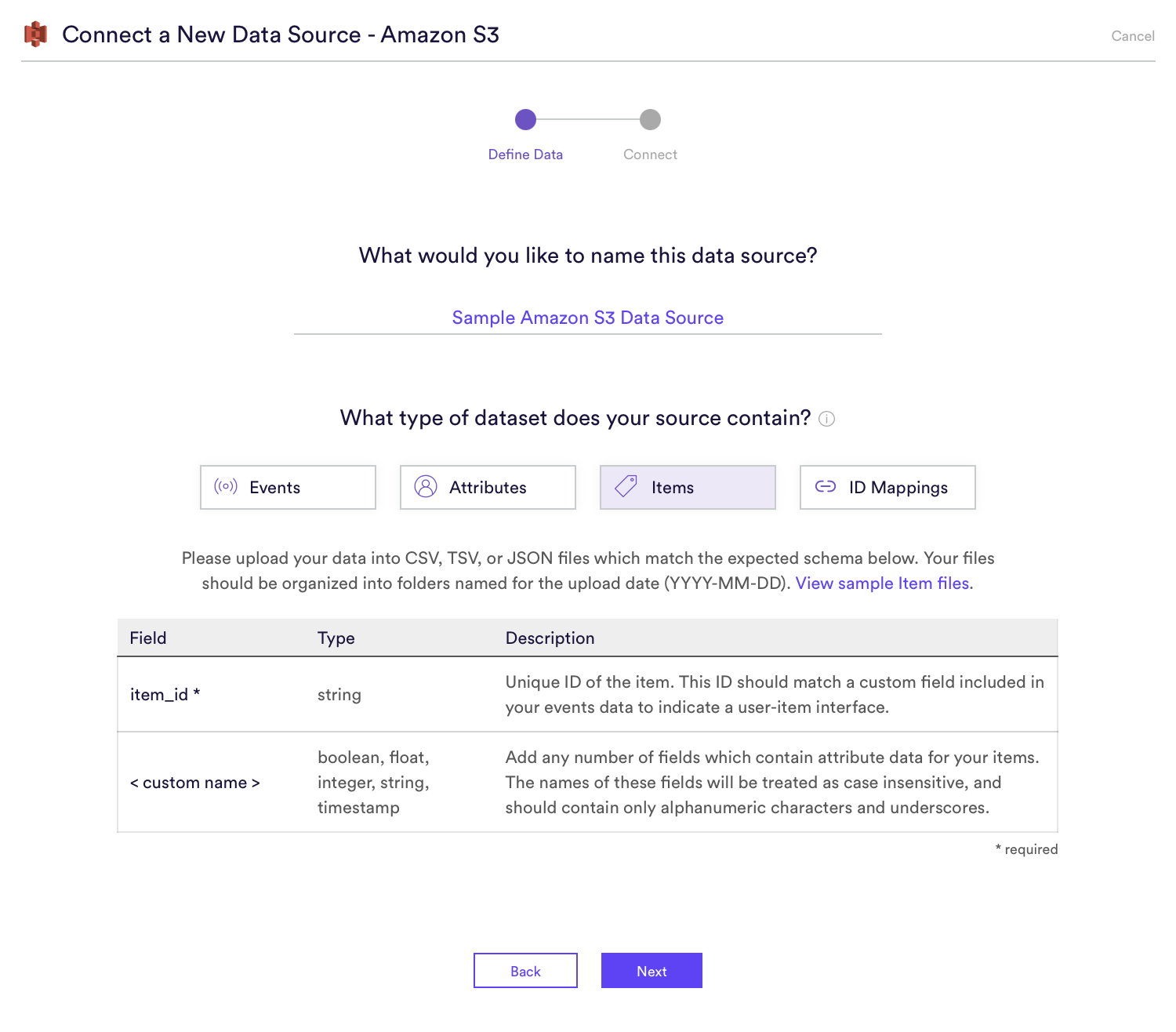
Step 2: Define Data
Name your Data Source, and specify which type of dataset it contains. If your S3 bucket contains multiple types of data, you should create a separate Data Source in Cortex for each one.
| Dataset | Description | Example |
| Events | Timestamped actions taken by your users. | Customer ABC completes a purchase event at time T. |
| Attributes | Characteristics or traits of your users. | Customer ABC has job title ‘Professor’, and age 49. |
| Subscriptions | Records of which users subscribed to which offerings and when. | Customer ABC has subscription ‘Premium’ with start time T and end time null. |
| Items | Metadata attributes for the items that your users interact with, via events. | Item XYZ has category ‘shoes’, and price 49.99. |
| ID Mappings | Associations between one set of IDs and another. | Customer ABC has cookie ID 123. |
Once you’ve specified which type of dataset your source will provide, Cortex will display a set of schema requirements to which your data must conform. This data should be uploaded to your S3 bucket in CSV, TSV, or JSON files (zipped or unzipped). Click the View Sample <Dataset Type> Files link in Cortex to see and download example files for each dataset type.
Additionally, these files should be organized into subfolders that are named based on the date that the data was gathered (YYYY-MM-DD). For example, the file path for a set of events data from May 3rd, 2021 might look like:
Example Upload:
s3://my-bucket/my-events-folder/2021-05-03/sample_events_file.csv
Step 3: Authorize Cortex to Access Your S3 Bucket
Before connecting your Data Source, you must first authorize Cortex to access your S3 bucket. This can be done by logging into your AWS IAM console in a new browser window, and taking the following steps.
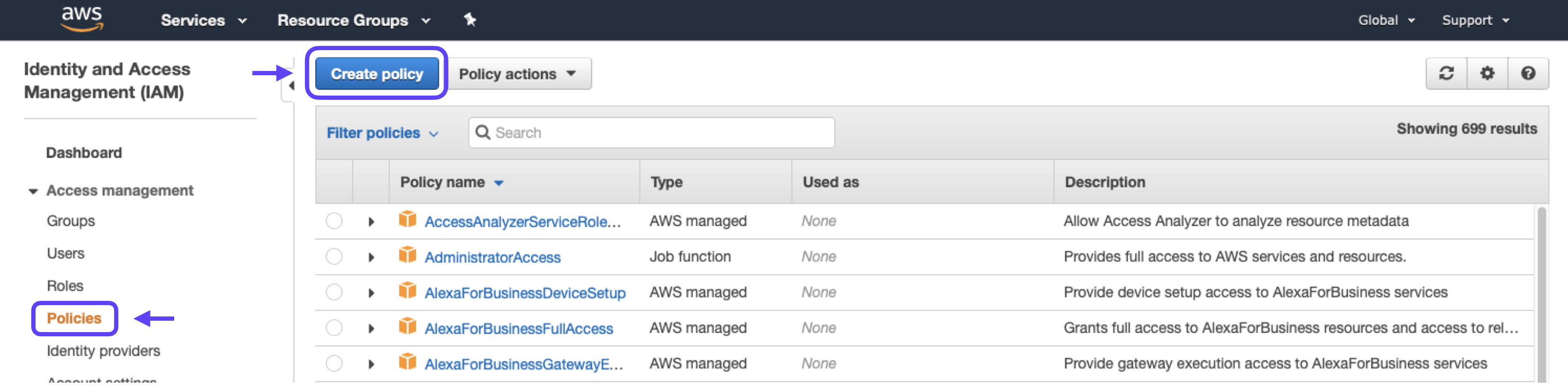
Create Policy
First, create an IAM policy which specifies the actions that policyholders are allowed to take on your S3 bucket. Later, you’ll attach this policy to an IAM role created for Cortex.
1. Go to the Policies section and click the Create Policy button.
2. Copy-paste the following into the JSON tab. Make sure to replace the YOUR-BUCKET-NAME placeholder with the name of your own S3 bucket.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::<YOUR-BUCKET-NAME>/*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::<YOUR-BUCKET-NAME>"
}
]
}
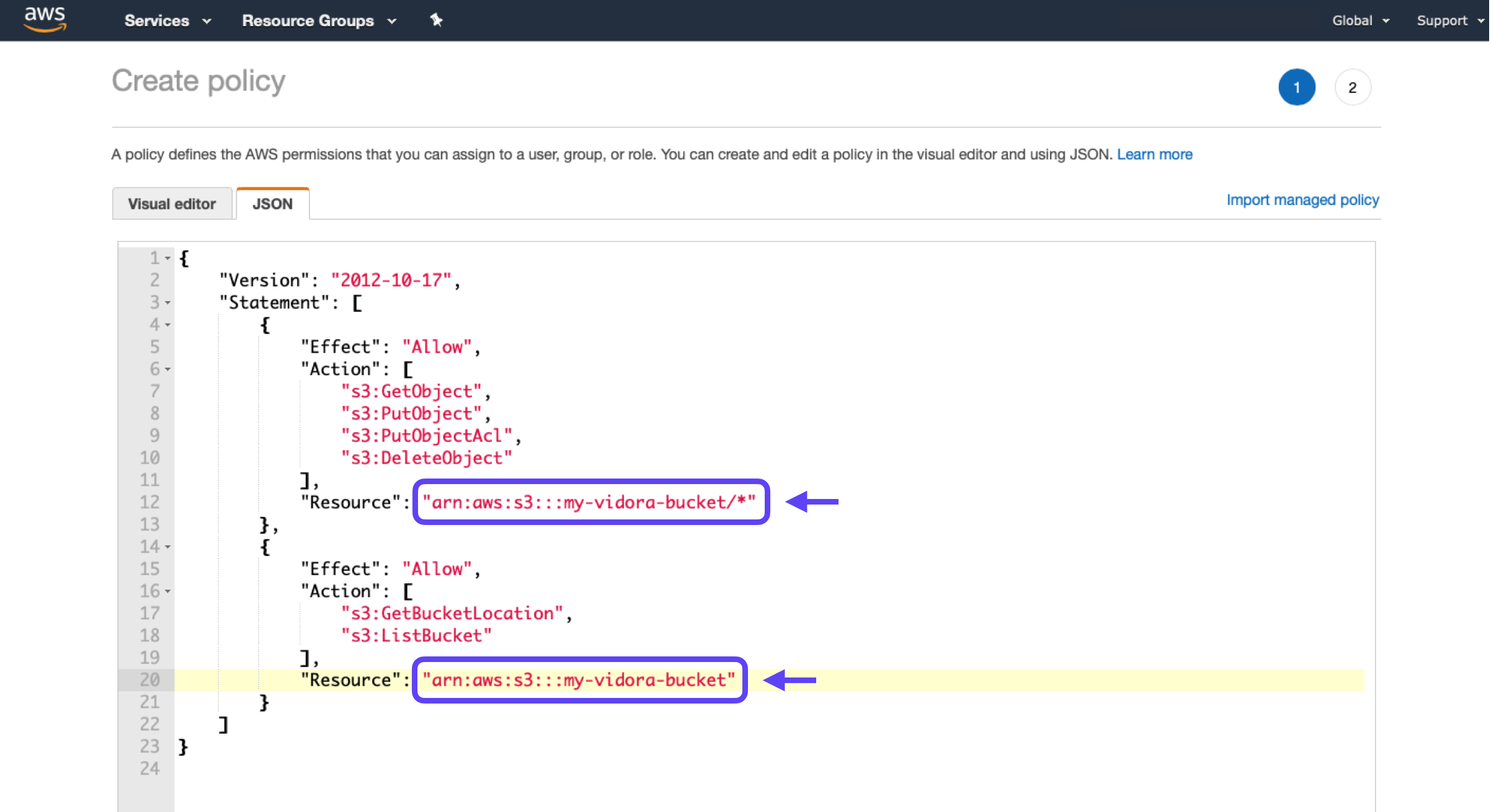
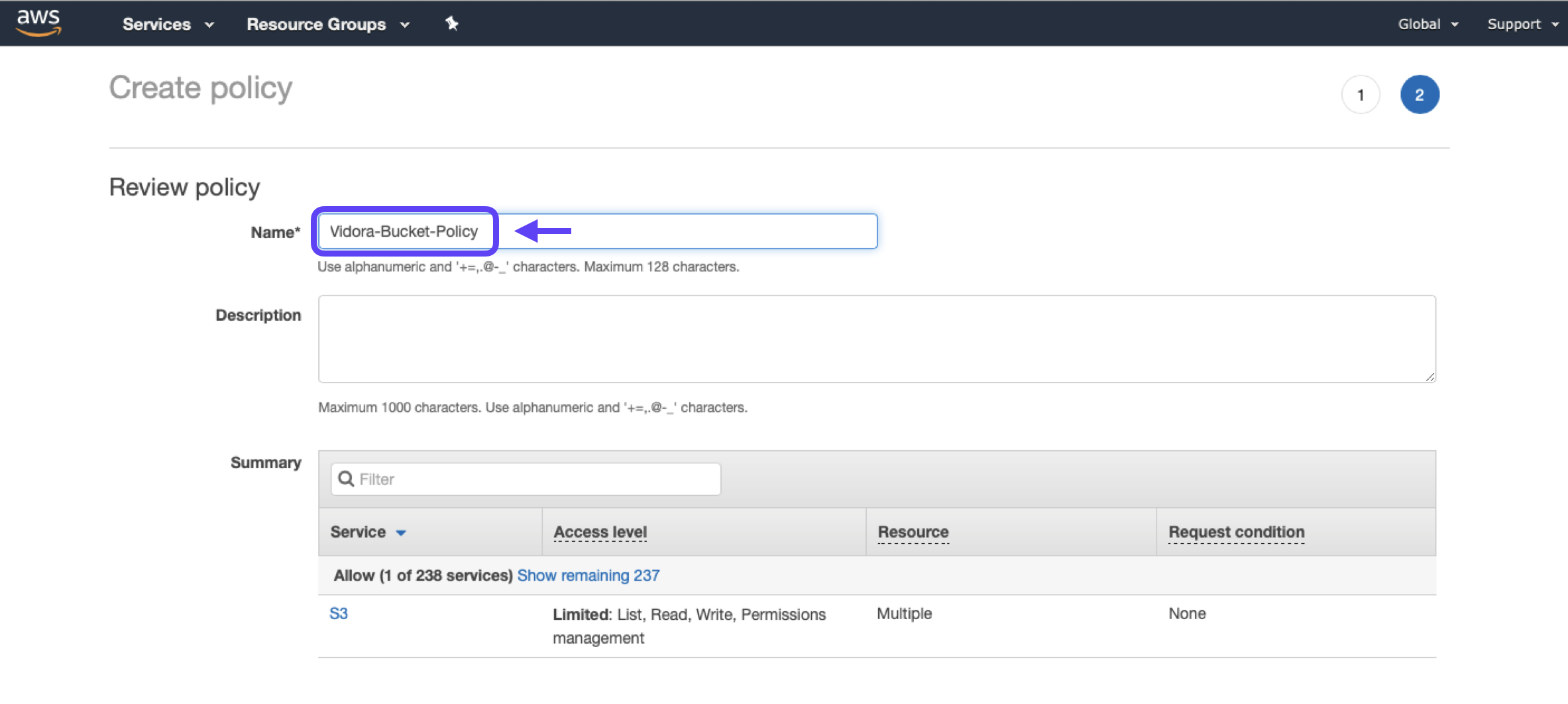
3. Click Review Policy, and provide a name and description for your policy. Make note of your policy’s name (e.g. “Vidora-Bucket-Policy”), and hit Create Policy.
Create Role
Next, create an IAM role which links your newly created policy with Cortex’s AWS account. This authorizes Cortex to take the actions specified in your policy.
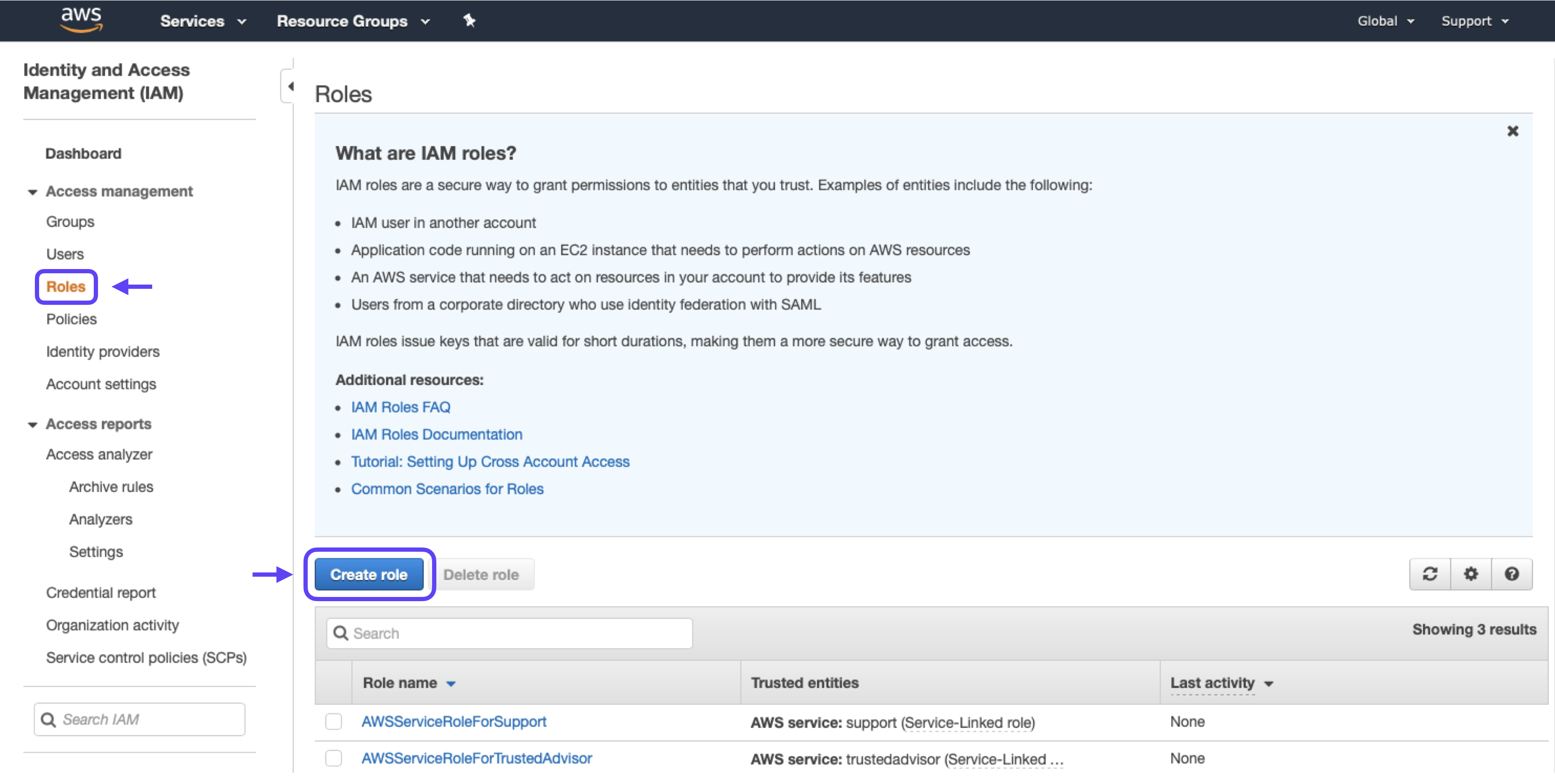
1. Go to the Roles section and click the Create New Role button.
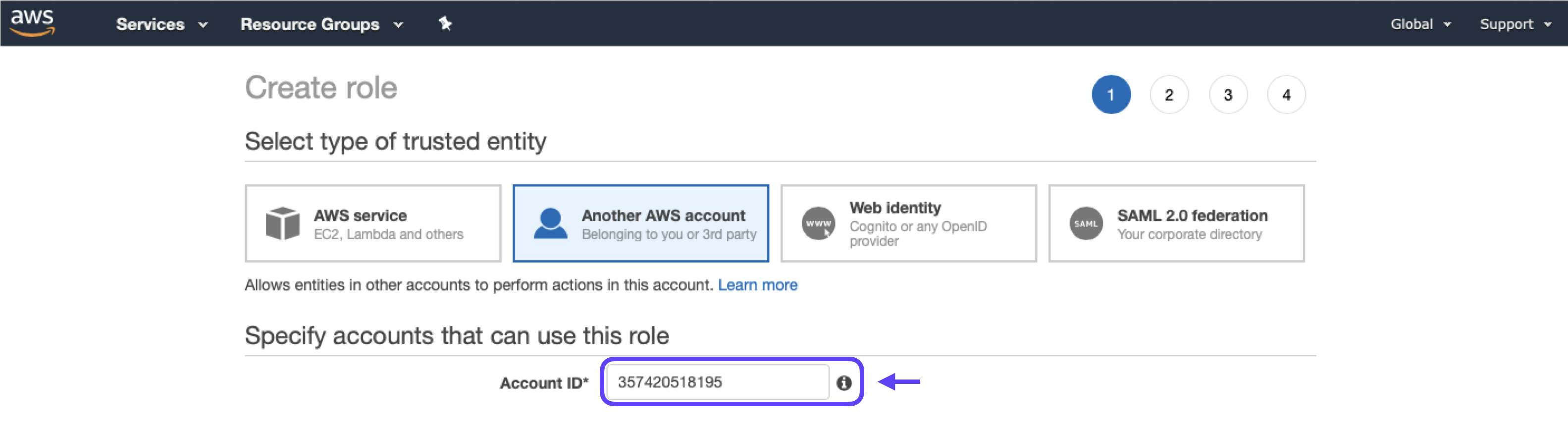
2. Select Another AWS Account, then enter 357420518195 (Cortex’s AWS account ID) in the Account ID field.
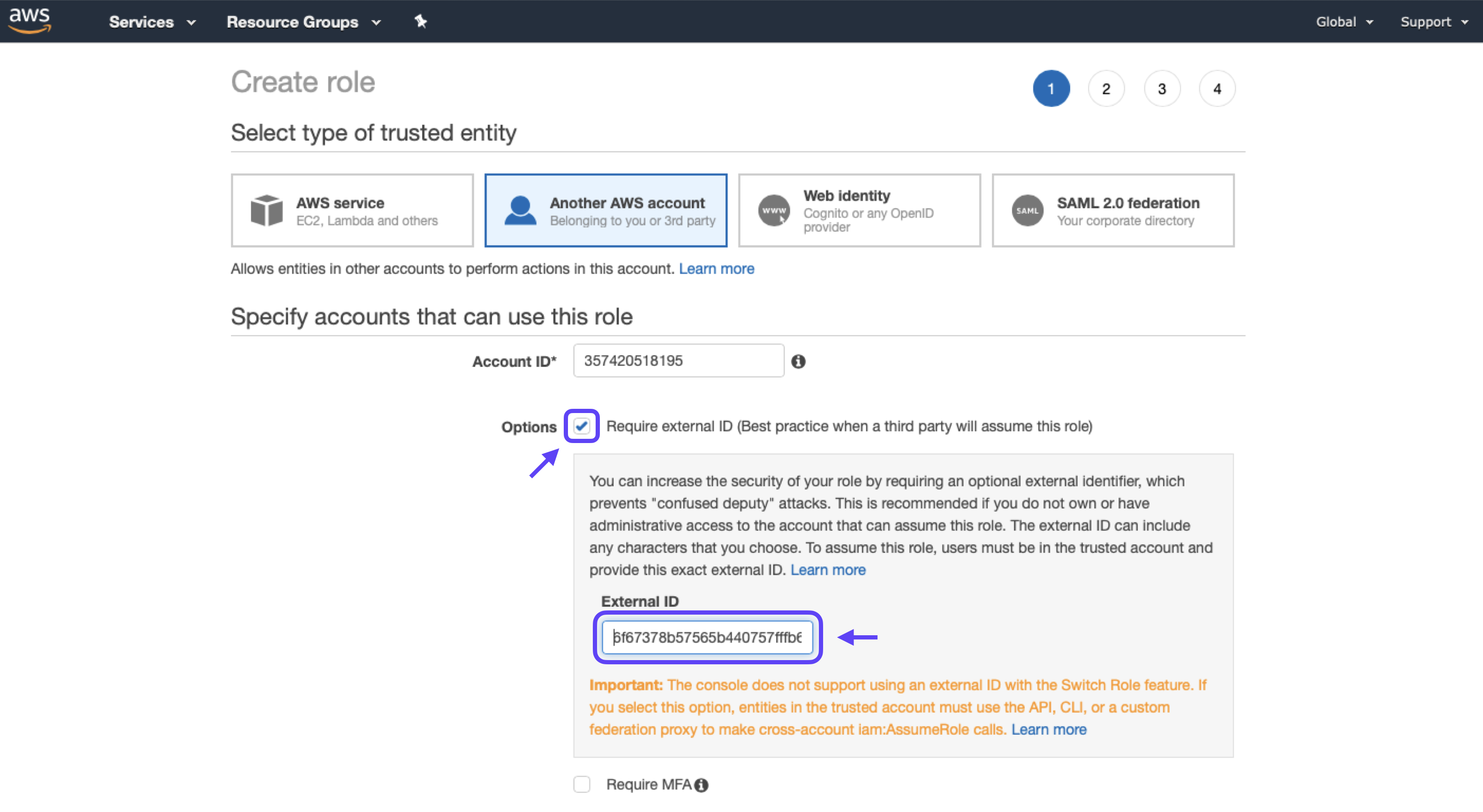
3. Check the “Require External ID” button, and enter the External ID listed in your Cortex account on the “Connect a New Amazon S3 Destination” page.
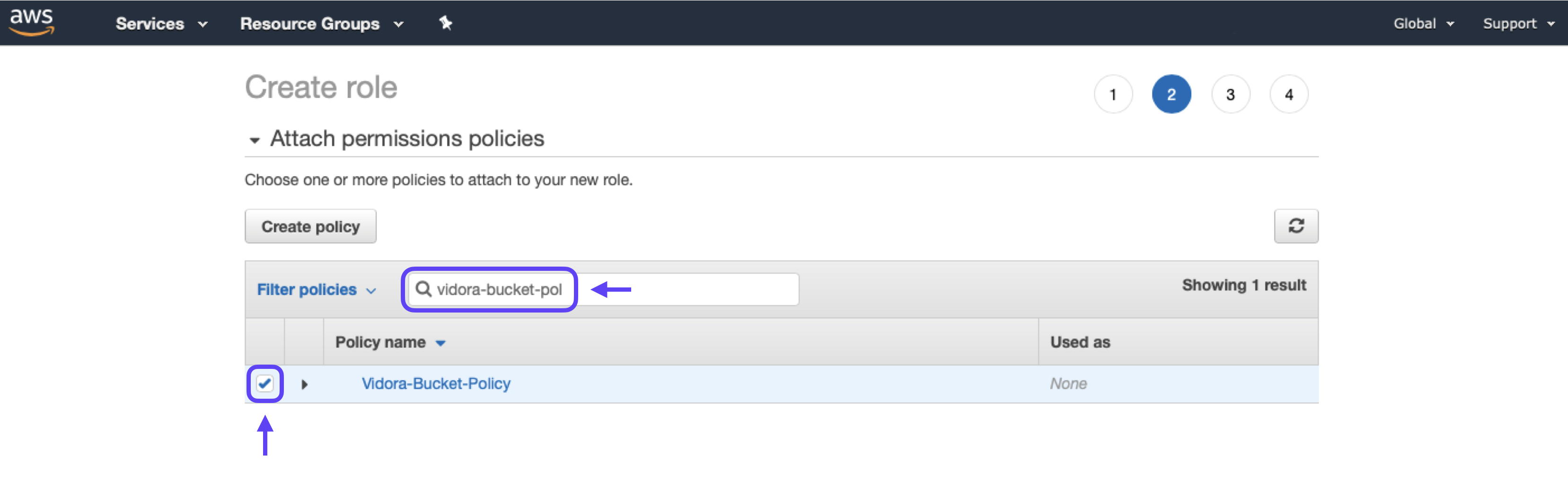
4. Proceed to the Permissions page, and search for the name of the Cortex policy that you created earlier. Click the check-box next to your policy in order to attach it to this role.
5. Proceed to the Tags page. Applying tags to your role is optional.
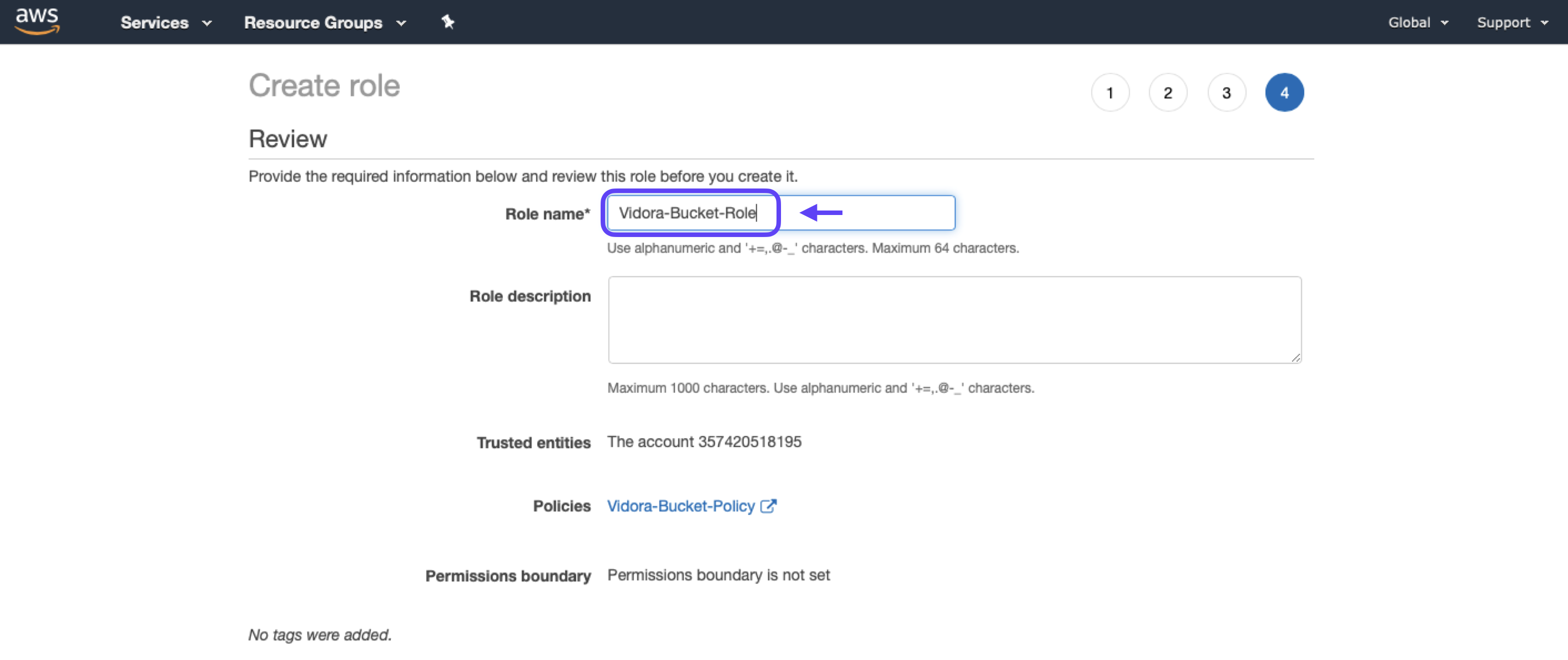
6. Name your new role (e.g. “Vidora-Bucket-Role”), then click Create Role.
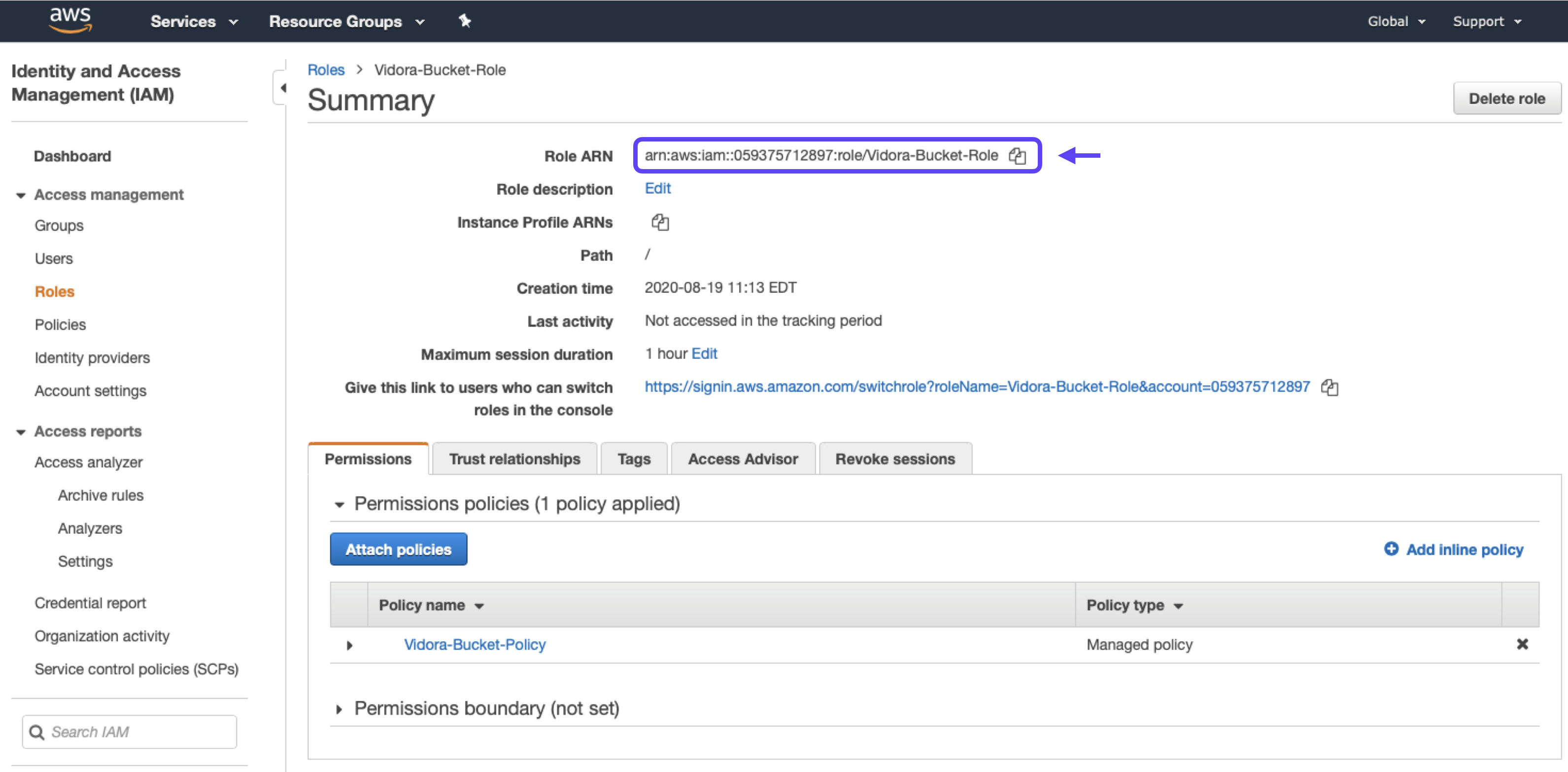
7. Click into your newly created role, and make note of the Role ARN – you will need to enter this in Cortex before activating your integration.
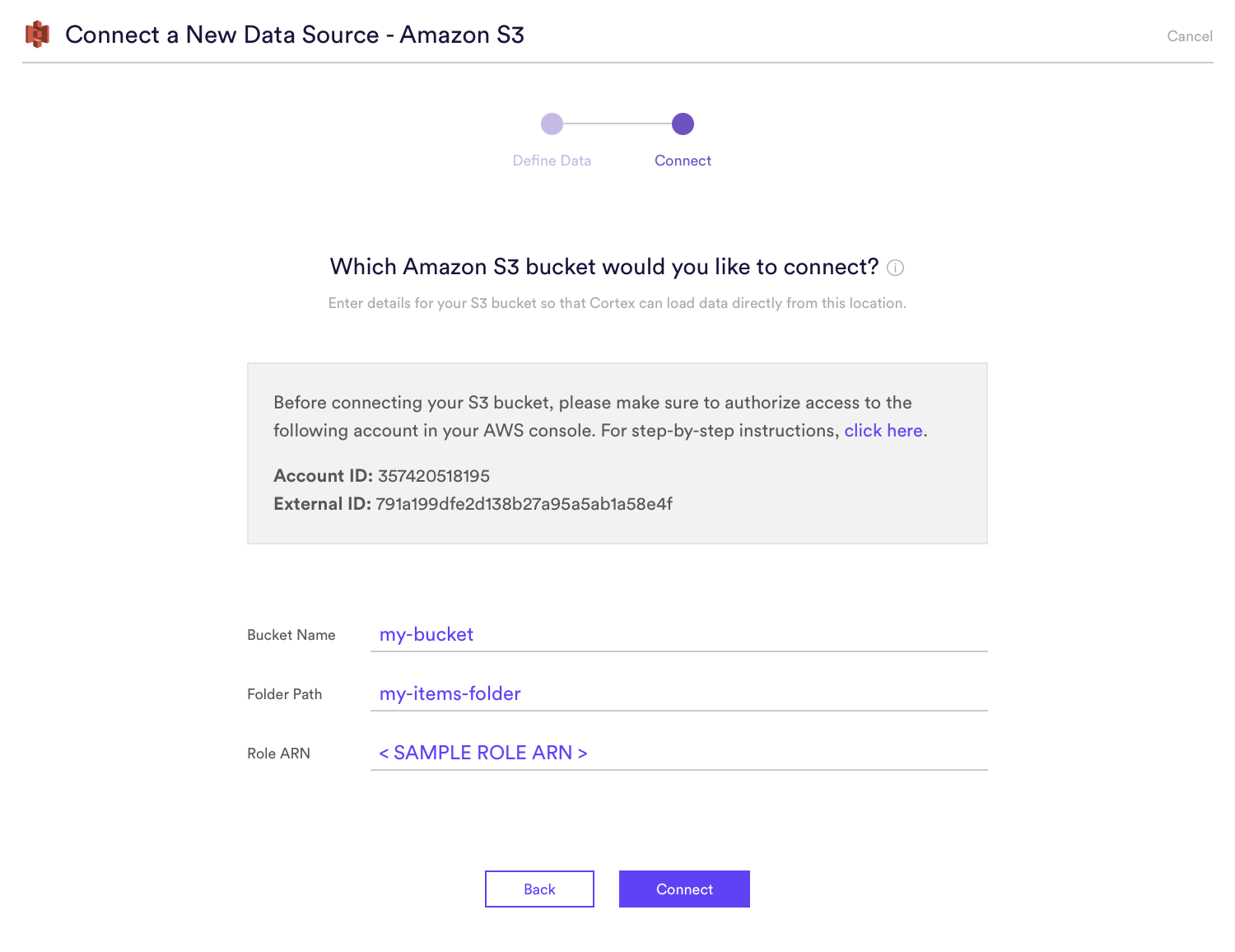
Step 4: Connect Your Bucket
Once you’ve authorized Cortex to access the bucket, head back to your Cortex account and hit “Next” to proceed to the Connect step. On this screen, enter the name and folder path of your S3 bucket, as well as the ARN for the role that you just created. See below for an example.
Step 5: Activate the Connection
After you’ve entered your bucket details, hit “Connect” to activate the integration. Cortex will automatically test whether the connection is valid before creating the Data Source.
Once your Data Source is live, any valid file that is uploaded into your S3 bucket will be ingested into Cortex. You may click into your newly created Data Source in order to view information about its schema, and a snapshot of sample data recently received by Cortex.
Related Links
Still have questions? Reach out to support@mparticle.com for more info!